如何用好PostgreSQL的备份与恢复?,
如何用好PostgreSQL的备份与恢复?
作者
赵成
日期
2017-10-22
标签
PostgreSQL , 数据库高可用 , 备份与恢复
高可用性是数据库的关键指标,简单说就是要做到故障时间短,数据不丢失,能够回退到指定位置(时间/事务)。实现高可用的基础是数据库的备份与恢复技术。
PostgreSQL备份与恢复操作涉及的参数和相关文件较多,内部逻辑关系较复杂,恢复分类方式容易混淆,这些都会影响到PostgreSQL高可用方案的实现。
本文首先介绍通常的数据库故障场景与处理方案,然后通过梳理PostgreSQL数据库备份与恢复的相关文件、参数配置与主要流程,对PostgreSQL恢复方式进行了清晰分类,最后给出了应对典型故障,PostgreSQL备份与恢复的配置方案。
一、故障场景和处理方案
数据库采用数据文件加日志文件,两份数据的存储方式。为提高性能,数据库运行时操作的数据位于内存缓冲区,缓冲区的数据延迟写入数据文件,因此数据文件会处于不一致的状态。数据的变更记录称为日志记录,日志记录以日志文件方式存储在磁盘上。日志记录也是先写入日志缓冲区,再写入日志文件。通过两个简单的规则Write-ahead log(将数据写入数据文件前,先将对应的日志记录写入日志文件)和Force log at commit(事务提交时,将其所有日志记录写入日志文件),可以保证通过日志文件完整的恢复数据文件。
传统的故障类型包括事务内部故障、系统故障、介质(磁盘)故障。对于事务内部故障和系统故障,数据库使用日志文件自动恢复,不需要人工干预。为应对介质故障,DBA需事先备份数据,发生故障后,使用备份数据恢复数据库。
可靠的磁盘设备可以大幅降低介质故障概率,但不能减少数据备份工作。一个常见的故障是数据误操作,即修改了不应该修改的数据。从数据库的角度看,误操作是正常的操作,不会进行自动恢复,只有使用备份数据才能恢复。同时,提供一段时间内历史数据的访问,也是一个常见的需求。
数据的备份与恢复可以分为逻辑与物理两种方式。
- 逻辑备份与恢复:备份时,使用工具将数据全量导出为外部文件,恢复时,使用工具,将备份文件导入新建的数据库
- 物理备份与恢复:备份时,配置实例处于归档模式,将生成的日志文件保持到指定位置。使用热备工具直接拷贝数据的数据目录,作为基线数据。恢复时,使用基线数据和日志文件将数据恢复到一致的状态。
逻辑方式不支持增量方式,适用于数据较小情况下的备份与恢复。物理方式支持增量备份,适合大数据量的备份与恢复。本文只讨论物理备份与恢复,下图为物理备份与恢复的基本流程。
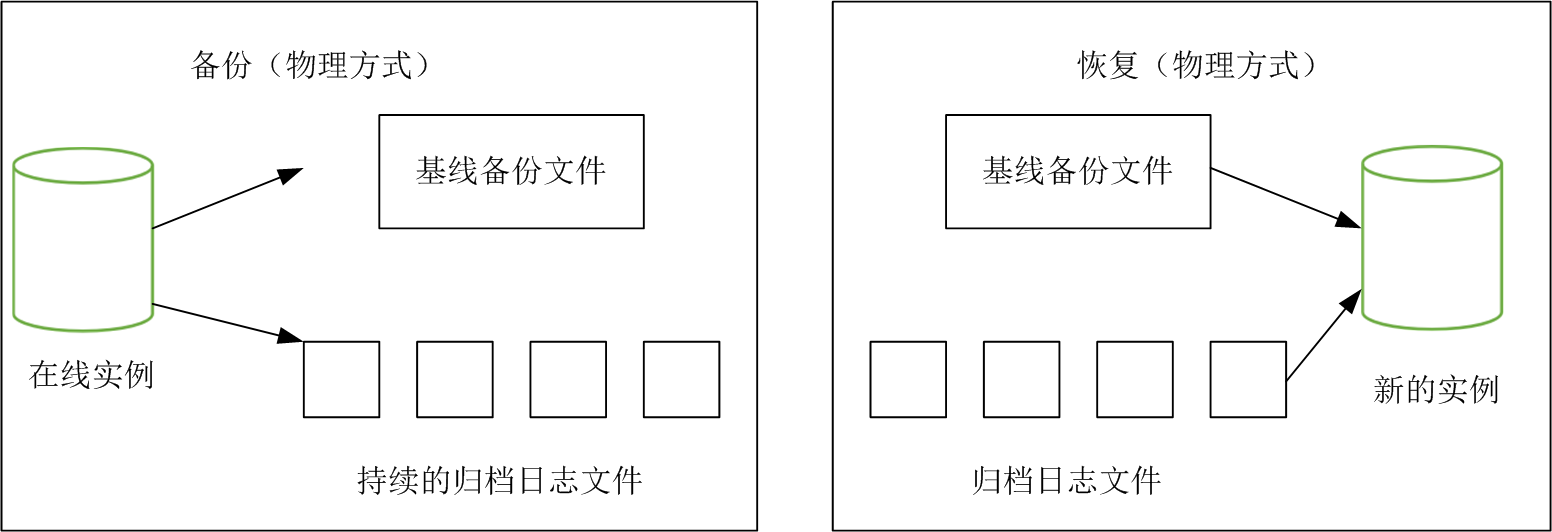
在高可用需求中,当单台实例发生故障,需要快速提供备用实例。备份基线数据+日志文件的方式无法满足时间要求。通常采用主备(master/slave)方案,master与slave通过日志流复制进行同步,slave可以提供只读数据访问,当master发送故障后,直接将应用请求转发到slave。
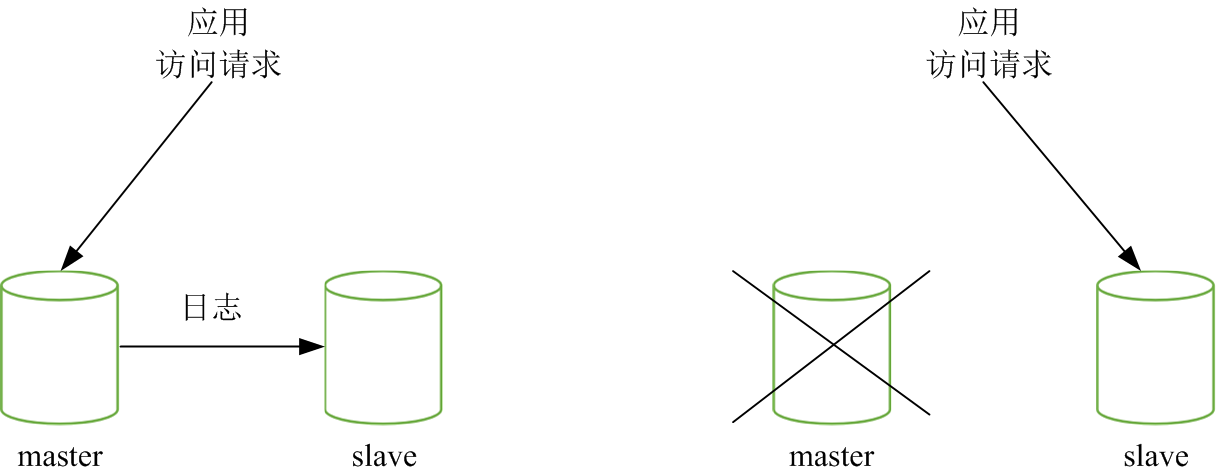
在高可用方案中,需要支持介质故障恢复,实时故障切换,误操作数据恢复,查看历史数据等功能。流复制技术和物理备份与恢复的结合,可以满足数据库高可用的基本要求。
| - | 流复制 | 物理备份与恢复 |
|---|---|---|
| 介质故障恢复 | 支持 | 支持 |
| 实时故障切换 | 支持 | 不支持 |
| 误操作数据恢复 | 不支持 | 支持 |
| 查看历史数据 | 不支持 | 支持 |
二、PostgreSQL备份与恢复相关文件、参数配置与主要流程
1.PostgreSQL日志文件的命名
日志序号 (lsn:log sequence number) 标识日志记录在日志文件中的位置。lsn是一个64位的整数。PostgreSQL运行时生成的日志文件存放在数据目录下的pg_xlog目录,每个日志文件称为一个segment,日志文件大小固定,由wal_segment_size参数指定,日志文件内部划分为多个wal page,每个page的大小由wal_block_size参数指定。
对于一个64位的lsn,可以计算出其所在的xlog文件名。lsn可以划分segment序号高位,segment序号低位和块内序号三个部分。对于segment大小为64M和16M的情况如下:
16M:segment序号高位(32比特)+segment序号低位(8比特)+块内序号(24比特)
64M:segment序号高位(32比特)+segment序号低位(6比特)+块内序号(26比特)
Xlog文件名由三部分组成,格式为:时间线+segment序号高位+segment序号低位,每个部分都表示为一个8位16进制数字。取出lsn中的segment高位和segment低位数值,就可以确定其所在的xlog文件。
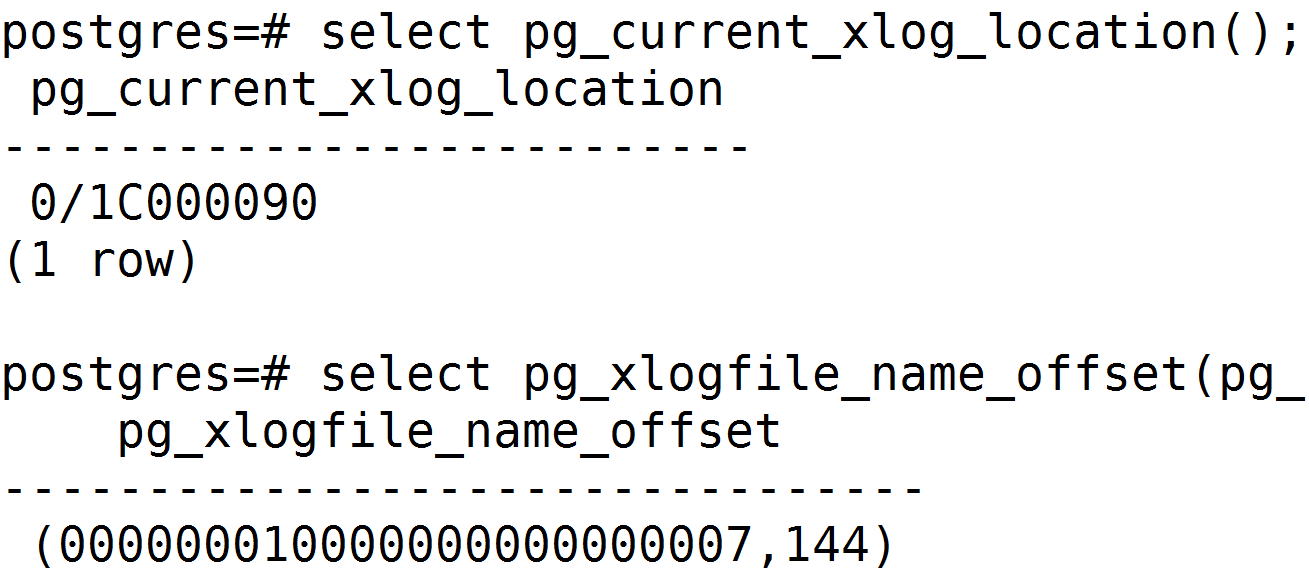
使用pg_current_xlog_location()查询当前lsn为0/1C000090(16进制高32位/16进制低32位),当前时间线为1,wal segment大小为64M,
根据64M大小日志文件名格式,可计算出lsn的segment序号高32位为0x0,segment序号低位为0x7, 块内序号为0x90,xlog文件名为000000010000000000000007
使用pg_xlogfile_name_offset()可以查询lsn对应的文件名文件内偏移,与上述计算一致。
2.checkpoint与control文件
PostgreSQL的数据文件和日志文件互为冗余。当某lsn之前的操作已经全部写入了数据文件后,则该lsn号之前的日志文件可以丢弃。checkpoint机制实现此功能。
checkpoint操作在以下场景执行:管理员手工执行check命令、数据库启动完成恢复、数据库正常关闭,以及后台Checkpoint进程的定期执行。
checkpoint流程可以简单描述为,首先构造checkpoint记录(redo字段为当前已写入日志文件的lsn),然后将数据缓冲区中的脏数据写入磁盘,最后写入checkepoint日志记录(包含checkpoint记录),并将checkpoint记录写入control文件。
512字节的control文件是PostgreSQL的关键数据,用于数据库启动时,判断数据库状态和恢复位置。controlfile文件中记录了数据库的状态,最近checkpoint记录,最小恢复lsn信息和基本的参数配置。数据库的状态包括:
- DB_SHUTDOWNED(数据库正常关闭)
- DB_SHUTDOWNED_IN_RECOVERY(数据库在恢复时关闭)
- DB_SHUTDOWNING(数据库启动到正常关闭过程中崩溃)
- DB_IN_CRASH_RECOVERY(数据库在恢复过程中崩溃),
- DB_IN_ARCHIVE_RECOVERY(数据库处于归档恢复)
- DB_IN_PRODUCTION(数据库处于正常工作状态,等待接受事务处理)
3.日志文件的生成与归档
PostgreSQL日志文件的segment序号从1开始,一个日志文件写完后,会写入下一个序号的日志文件。checkpoint之后,最近一次checkpoint.redo lsn之前的日志文件可以丢弃。PostgreSQL会循环使用日志文件。checkpoint操作中,会将可丢弃的日志文件改名为未来的日志文件名,并该日志文件重新初始化。PostgreSQL在写新的日志文件时,如果该文件已存在,则使用该文件,否则才会创建新的文件。因此不能从pg_xlog目录中的文件名直接判断当前的日志文件,需要使用pg_current_xlog_location和pg_xlogfile_name_offset函数进行判断。
为持久保存日志文件,需要开启日志归档模式。在该模式下,可丢弃日志文件被删除前,被拷贝到指定目录。在postgres.conf配置文件中设置三个参数:
wal_level=replica 或更高
archive_mode = on
archive_command = 'cp %p /mnt/server/archivedir/%f'
%p表示pg_xlog目录路径和日志文件名,%f表示日志文件名。 日志被拷贝到/mnt/server/archivedir目录
日志的归档过程如下:
- checkpoint操作中,当一个日志文件X可丢弃时,在pg_xlog的archive_status目中生成X.ready文件。
- 后台archive进程负责日志文件的拷贝。该进程监控archive_status目录,当发现有X.ready文件名后,使用archive_command拷贝文件,并将X.ready命名为X.done
- 下一次checkpoint操作中,将archive_status目中X.done对应的X日志文件改名。
4.crash recovery
PostgreSQL正常运行中,直接kill主进程,重启PostgreSQL,将进入crash recovery处理流程,从control文件中checkpoint的redo lsn位置开始,
使用pg_xlog目录中的日志文件进行恢复。PostgreSQL能进行上述处理,是因为将其状态和最近的checkpoint记录在在control文件中。
初始化数据库后,control文件DB状态初始值为shutdown。pg启动时,当control文件DB状态为shutdown,则将状态设置为production,退出恢复过程。在正常关闭服务时,执行checkpoint,并将control文件DB状态设置shutdown。pg启动时,当control文件DB状态为production,则说明发生了crash,会从control文件读取最近checkpoint,从redo lsn开始进行恢复,恢复完成后,将状态设置为production。
5.热备
备份分为冷备和热备。冷备是正常关闭服务后拷贝文件。热备是服务正常运行中拷贝文件。由于采用数据缓冲区机制,拷贝的文件数据会不一致。根据数据库恢复基本原理,只要确定某lsn之前的日志已经全部写入了数据文件,则在拷贝后的数据文件上,应用该lsn号之后的日志文件,可将数据恢复到一致的状态。
热备包括以下步骤
- 执行pg_start_backup函数:该函数执行checkpoint,将checkpont信息写入数据目录下的backup_label文件。
- 拷贝数据目录到指定位置
- 执行pg_stop_backup函数:该命令删除backup_label文件,写XLOG_BACKUP_END日志,并在pg_xlog目录中写入backup文件,该文件记录了热备开始和结束的lsn信息。
backup文件格式为:热备开始lsn对应的日志文件名.开始lsn的块内偏移.backup
6.使用归档日志恢复
Crash recovery只能使用pg_log目录中的日志文件进行恢复,启用archive recovery模式后,可以使用其它目录的日志文件(归档日志文件)进行恢复。
在数据目录存创建recover.conf文件,PostgreSQL启动时,读取到该文件,会进入archive recovery流程。在recover.conf中设置日志拷贝命令restore_command,pg恢复过程中,使用该命令将归档日志拷贝到pg_xlog目录后进行恢复。
restore_command = 'cp /mnt/server/archivedir/%f "%p"'
%f表示日志文件名 %p表示目标路径和文件名
7.使用流复制恢复
流复制可以视为archive recovery的一种情况。使用归档日志文件进行恢复时,备机需要获取主机一个完整xlog文件,才可进行恢复。在流复制中,主机产生日志记录后,会及时发送到备机。
在slave节点数据目录的recover.conf中,配置到主机的连接信息primary_conninfo并设置standby_mode为on。
standby_mode = 'on'
primary_conninfo = 'host=192.168.1.50 port=5432 user=foo password=foopass'
master节点的postgres.conf文件中指定wal_level和发送日志进程的数目max_wal_senders。
wal_level=replica 或更高
max_wal_senders=5
在master的pg_hba.conf文件中允许复制连接建立
host replication postgres 192.168.10.0/24 trust
slave启动后会启动wal reciver进程,根据primary_conninfo向master发送连接请求。master收到请求后,启动wal sender进程,wal sender与reciver建立连接。 wal reciver将起始的lsn信息发送给wal sender,wal sender从该lsn开始,将日志记录持续发送给wal reciver,wal reciver将日志写入pg_xlog目录中的日志文件,并通知恢复进程读取文件进行恢复处理。
8.恢复的退出与时间线
Crash recovery模式下,应用完pg_xlog目录中的所有可用日志文件后,自动退出恢复,进入运行状态。Archive recovery模式下,recovery.conf文件中参数standby_mode为off时,应用完所有日志后,自动退出恢复,进入运行状态。standby_mode为on时,应用完所有日志后,恢复流程不会退出,持续读取可用日志(来自于归档日志文件或流复制),当收到pg_ctl工具发出的promote命令后,才退出恢复流程,进入运行状态。
可以通过设置Recovery Target,使得archive recovery在指定的位置(时间或事务号)停止恢复。在recovery.conf文件配置如下参数,表示恢复流程在恢复完123947事务后结束。
recovery_target_xid = '123947'
时间线(Timeline)是PostgreSQL中的特有的概念。其初始值为1,退出archive recovery时,timeline增1,退出crash recovery时,timeline不变。Timeline反映在日志的文件名中,日志文件的命名格式为:时间线号+segment序号高位+segment序号低位。
引入时间线概念后,日志位置的唯一标识从lsn变为时间线+lsn,checkpoint的结构中记录了当前的timeline。
发生时间线切换时,在pg_xlog目录写入时间线history文件,文件名为"当前timelime.history",文件内记录了时间线切换的历史纪录,每一行记录一条时间线信息,格式为。
parentTLI为时间线id,为切换发生后的lsn,为发生切换的原因。
从时间线history文件中,可以计算出每条时间线的开始和结束lsn。
时间线文件00000003.history,内容为
1 0/14000060 no recovery target specified
2 0/140420D0 no recovery target specified
该文件含义为当前时间线为3,时间线1的lsn范围[0/0,0/14000060),
时间线2的lsn范围[0/14000060,0/140420D0),时间线3从0/140420D0开始。
使用timeline有以下优点:
- 切换逻辑显得清晰。从时间线history文件,可以计算出每条时间线的开始和结束lsn。
- 避免归档日志的覆盖。当备机与主机的归档目录相同时,备机升级为主机后,生成的日志文件名与原主机不同(时间线不同),拷贝到归档目录后,不会覆盖之前的日志文件。
9、pg_basebackup、pg_rman工具
pg_basebackup和pg_rman为备份与恢复提供良好的操作管理界面,避免手工管理配置文件。
pg_basebackup是PostgreSQL自带的一个远程热备工具,可以将远程PostgreSQL热备到本地目录。其工作流程为,连接到一个远程PostgreSQL,执行pg_start_backup,将整个数据目录传输到本地,执行pg_stop_backup命令。
将地址为192.168.0.1的PostgreSQL,备份到本地usr/local/pgsql/data目录
pg_basebackup -h 192.168.0.1 -U test -D /usr/local/pgsql/data
pg_basebackup支持在目标数据目录生成用于流复制的recovery.conf文件。
pg_basebackup -h 192.168.0.1 -U test -R -D /usr/local/pgsql/data
会在/usr/local/pgsql/data目录生成流复制所用的postgresql.conf文件,内容如下
standby_mode = 'on'
primary_conninfo = 'host=192.168.0.1 user=test'
pg_rman是PostgreSQL的备份与恢复工具,支持全量、增量、归档三种备方式,支持数据压缩与备份集管理。pg_rman适用于大数据量数据库的增量备份。pg_rman必须与被备份数据库安装在同一台机器。其备份流程为,连接到本地PostgreSQL,执行pg_start_backup,全量备份文件或者通过比较数据文件块的lsn号进行增量备份,执行pg_stop_backup命令,备份归档日志。
pg_rman 恢复支持将数据恢复到指定时间、事务号和时间线参数,流程为其将对应的全量数据和归档日志拷贝到相应目录,并配置recovery.conf文件的restore_command参数,standby_mode为off。
pg_rman支持的命令包括
- 初始化 pg_rman init
- 全量备份 pg_rman backup -b full
- 增量备份 pg_rman backup -b incremental
- 恢复 pg_rman restore
三、PostgreSQL数据库恢复分类
根据配置文件和参数的不同,PostgreSQL恢复可以做以下分类。
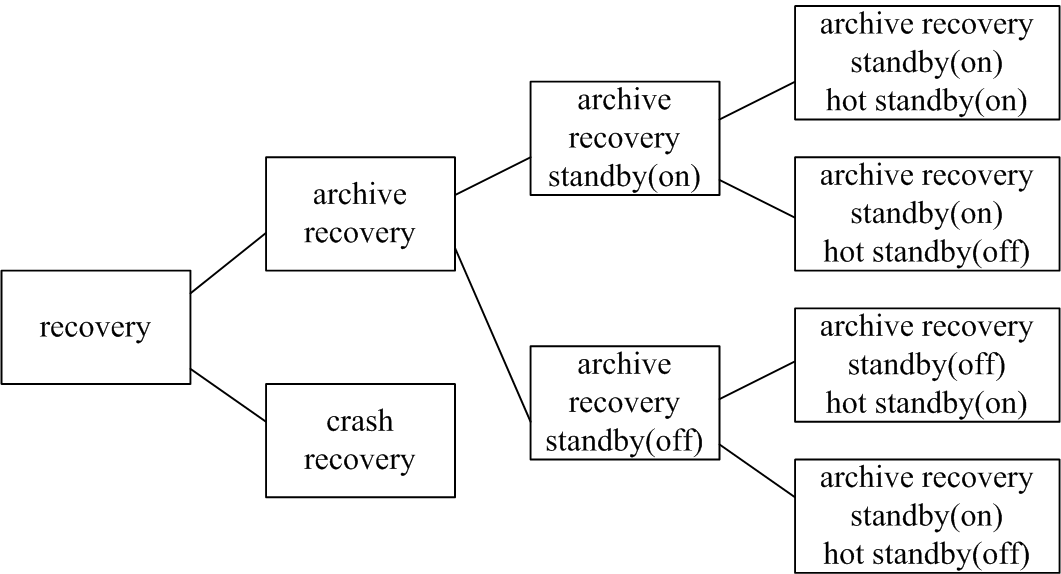
Crash recovery是PostgreSQL发生故障后自动进行的恢复处理,archive recovery是DBA通过配置recovery.conf文件,PostgreSQL启动后进入的恢复流程。
配置recovery.conf文件的standby_mode参数为on或off,可以控制进入standb模式还是非standby模式。非standby模式下,PostgreSQL恢复到指定位置或者发现没有可用日志记录时,停止恢复流程。standby模式下,在没有可用日志的情况下,会持续检查并应用可用日志,直到DBA发出promote命令。
配置postgresql.conf文件的hot_standby参数为on或off,可以控制是否开启hot standby模式。hot standby开启情况下,恢复结束前,数据库可对外提供只读访问。hot standby关闭情况下,恢复结束前,数据库不提供对外访问。
5种情况下配置文件与参数的不同:
- crash recovery:无recovery.conf文件
-
archive recovery:有recovery.conf文件,lable文件(可选)
- standby-hot standby:standby_mode为on,hot_standby为on
- standby-非hot standby:standby_mode为on,hot_standby为off
- 非standby-hot standby:standby_mode为off,hot_standby为on
- 非standby-非hot standby:standby_mode为off,hot_standby为off
对于流复制建议采用archive recovery-standby-hot standby配置,对于基线数据+归档日志恢复的配置,建议采用archive recovery-非standby-hot standby配置。
Recovery过程简单说就是从一个checkpoint的redo lsn位置开始,通过应用日志记录,使数据文件达到一致的状态。对于每一种恢复配置,要明确三个问题,从哪里找到开始的lsn与时间线,日志记录的来源是哪里,恢复状态如何退出。
Crash recovery模式下,从control文件读取checkpoint记录,其中包含redo lsn和时间线,从该位置开始恢复,日志记录只来自pg_xlog目录中的日志文件,当没有日志可以应用时,退出恢复。
Archive recovery模式下,当数据目录下不存在backup_label文件时,与crash recovery相同的方式从control文件读取redo lsn和时间线。当数据目录下存在backup_label文件时,redo lsn从该文件读取,根据timeline history文件,获取该redo lsn对应的时间线。
Archive recovery模式的非standby配置下,必须配置recovery.conf的restore_command命令,该模式下只能使用归档日志文件进行恢复。应用完所有的规定日志,或者指定位置时,恢复处理结束。
Archive recovery模式的standby配置下,至少配置recovery.conf的restore_command命令和primary_conninfo中的一个。该模式下可以使用归档日志文件或者流复制。当没有可用的日志记录时,会持续检查并应用可用日志,直到DBA发出promote命令。
在recovery.conf文件中,可以配置Recovery Target,使得archive recovery在指定的位置(时间、事务号或时间线)停止恢复。
四、PostgreSQL高可用方案中的备份与恢复
PostgreSQL高可用方案应能够满足介质故障恢复、实时故障切换、误操作数据恢复和查看历史数据的需求。
高可用环境的建立,包括以下工作:
配置主机启动日志归档和流复制主节点信息
postgres.conf(异步流复制)
wal_level=replica
archive_mode = on
archive_command = 'cp %p /mnt/server/archivedir/%f'
max_wal_senders=5 #发送wal进程数据
hot_standby=on
pg_hba.conf
host replication postgres 192.168.10.0/24 trust
建立备机并启动流复制
使用basebackup工具热备:
pg_basebackup -h 192.168.0.1 -U test -R -D /usr/local/pgsql/data
修改postgres.conf中的port和archive_command为备机端口和归档路径。启动备机,建立流复制。
以上配置下,备机恢复模式为archive recovery,开启standby,开启hot standby。
使用pg_rman工具为主机建立基线数据备份,并定期进行增量数据备份
- 初始化 pg_rman init -B 备份文件保存目录 -D 数据库数据目录
- 全量备份 pg_rman backup -B 备份文件保存目录 -D 数据库数据目录 -b full
- 增量备份 pg_rman backup -B 备份文件保存目录 -D 数据库数据目录 -b incremental
故障处理流程:
(1)在环境中配置状态监控工具,实时监控主机状态,主机不可用时,自动promte备机,并将数据库访问路由到备机。
(2)恢复历史数据
pg_rman restore命令支持将数据恢复到指定时间、事务号和时间线参数,该命令将对应的全量数据和归档日志拷贝到相应目录,并配置recovery.conf文件。
pg_rman restore执行完成后,启动PostgresSQL,进行恢复。
以上配置下,备机恢复模式为archive recovery,关闭standby,开启hot standby。
五、结尾
通过梳理PostgreSQL数据库备份与恢复流程的相关文件、参数配置与主要流程,对恢复方式进行了分类,给出高可用方案中备份与恢复的基本配置。完整的可用性方案中,还需要考虑主机状态监控,数据访问路由切换和故障主机复用等问题。
版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)