访问数据库总超时?这份避坑指南请收好,

本文转载自微信公众号「数仓宝贝库」,作者李玥 。转载本文请联系数仓宝贝库公众号。
01事故排查过程
电商公司大都希望做社交引流,社交公司大都希望做电商,从而将流量变现,所以社交电商一直是热门的创业方向。这个真实的案例来自某家做社交电商的创业公司。下面就来一起看下这个典型的数据库超时案例。
从圣诞节平安夜开始,每天晚上固定十点到十一点这个时间段,该公司的系统会瘫痪一个小时左右的时间,过了这个时间段,系统就会自动恢复正常。系统瘫痪时,网页和App都打不开,数据库服务请求超时。
如图1所示,该公司的系统架构是一个非常典型的小型创业公司的微服务架构。
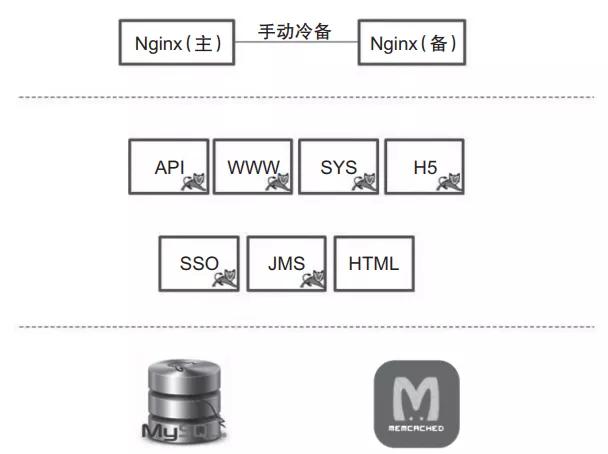
图1 典型的小型创业公司系统架构
该公司将整个系统托管在公有云上,Nginx作为前置网关承接前端的所有请求。后端根据业务,划分了若干个微服务分别进行部署。数据保存在MySQL数据库中,部分数据用Memcached做了前置缓存。数据并没有按照微服务最佳实践的要求,进行严格的划分和隔离,而是为了方便,存放在了一起。
这种存储设计方式,对于一个业务变化极快的创业公司来说是比较合理的。因为它的每个微服务,随时都在随着业务需求的变化而发生改变,如果做了严格的数据隔离,反而不利于应对需求的变化。
开始分析这个案例时,我首先注意到的一个关键现象是,每天晚上十点到十一点这个时间段,是绝大多数内容类App访问量的高峰期。因为这个时间段很多人都会躺在床上玩手机,因此我初步判断,这个故障可能与访问量有关。图2所示的是该系统每天各个时间段的访问量趋势图,正好可以印证我的初步判断。
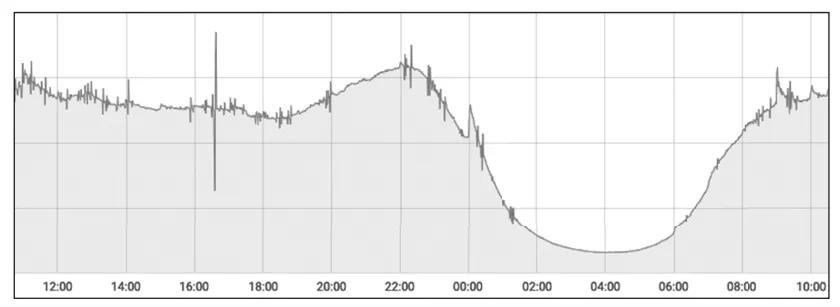
图2 系统访问量
基于这个判断,排查问题的重点应该放在那些服务于用户访问的功能上,比如,首页、商品列表页、内容推荐等功能。
在访问量达到峰值的时候,请求全部超时。而随着访问量的减少,系统又能自动恢复,因此基本上可以排除后台服务被大量请求冲垮,进程僵死或退出的可能性。因为如果进程出现这种情况,一般是不会自动恢复的。排查问题的重点应该放在MySQL上。
观察图3所示的MySQL服务器各时段的CPU利用率监控图,我们可以发现其中的问题。从监控图上可以看出,故障时段MySQL的CPU利用率一直是100%。这种情况下,MySQL基本上处于不可用的状态,执行所有的SQL都会超时。在MySQL中,这种CPU利用率高的现象,绝大多数情况下都是由慢SQL导致的,所以需要优先排查慢SQL。MySQL和各大云厂商提供的RDS(关系型数据库服务)都能提供慢SQL日志,分析慢SQL日志,是查找造成类似问题的原因最有效的方法。
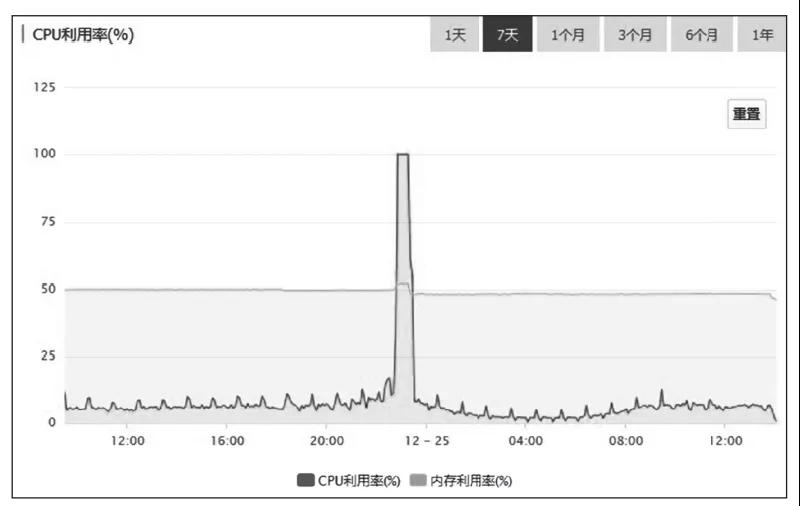
图3 MySQL服务器各时段的CPU利用率监控图
一般来说,慢SQL日志中,会包含这样一些信息:SQL语句、执行次数、执行时长。通过分析慢SQL查找问题,并没有什么标准的方法,主要还是依靠经验。
首先,我们需要知道的一点是,当数据库非常忙的时候,任何一个SQL的执行都会很慢。所以并不是说,慢SQL日志中记录的这些慢SQL都是有问题的SQL。大部分情况下,导致问题的SQL只是其中的一条或几条,不能简单地依据执行次数和执行时长进行判断。但是,单次执行时间特别长的SQL,仍然是应该重点排查的对象。
通过分析这个系统的慢SQL日志,我首先找到了一条特别慢的SQL。以下代码是这条SQL的完整语句:
- 1select fo.FollowId as vid, count(fo.id) as vcounts
- 2
- 3from follow fo, user_info ui
- 4
- 5where fo.userid = ui.userid
- 6
- 7and fo.CreateTime between
- 8
- 9str_to_date(?, '%Y-%m-%d %H:%i:%s')
- 10
- 11and str_to_date(?, '%Y-%m-%d %H:%i:%s')
- 12
- 13and fo.IsDel = 0
- 14
- 15and ui.UserState = 0
- 16
- 17group by vid
- 18
- 19order by vcounts desc
- 20
- 21limit 0,10
这条SQL支撑的功能是一个“网红”排行榜,用于排列出“粉丝”数最多的前10名“网红”。
请注意,这种排行榜的查询,一定要做缓存。在上述案例中,排行榜是新上线的功能,由于没有做缓存,导致访问量高峰时间段服务卡死,因此增加缓存应该可以有效解决上述问题。
为排行榜增加缓存后,新版本立即上线。本以为问题就此可以得到解决,结果到了晚高峰时间段,系统仍然出现了各种请求超时,页面打不开的问题。
再次分析慢SQL日志,我发现排行榜的慢SQL不见了,说明缓存生效了。日志中的其他慢SQL,查询次数和查询时长的分布都很均匀,找不到明显有问题的SQL。
于是,我再次查看MySQL服务器各时段的CPU利用率监控图,如图4所示。
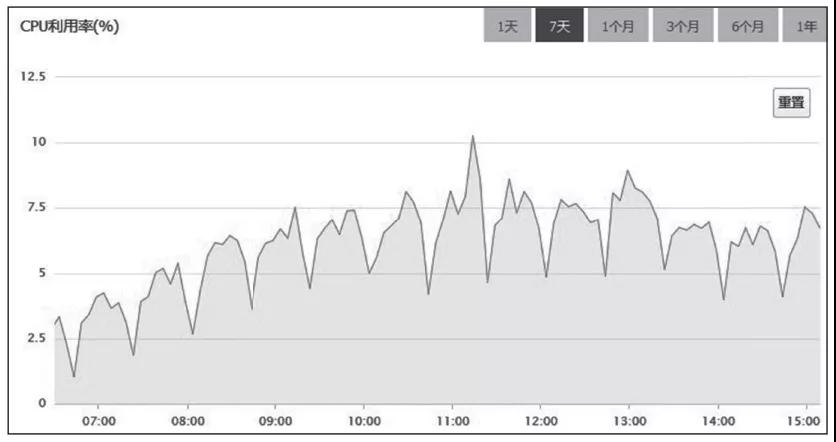
图4 系统增加缓存后,MySQL服务器各时段的CPU利用率
把图放大后,我又从中发现了如下两点规律。
1)CPU利用率,以20分钟为周期,非常有规律地进行波动。
2)总体的趋势与访问量正相关。
那么,我们是不是可以猜测一下,如图5所示,MySQL服务器的CPU利用率监控图的波形主要由两个部分构成:参考线以下的部分,是正常处理日常访问请求的部分,它与访问量是正相关的;参考线以上的部分,来自某个以20分钟为周期的定时任务,与访问量关系不大。
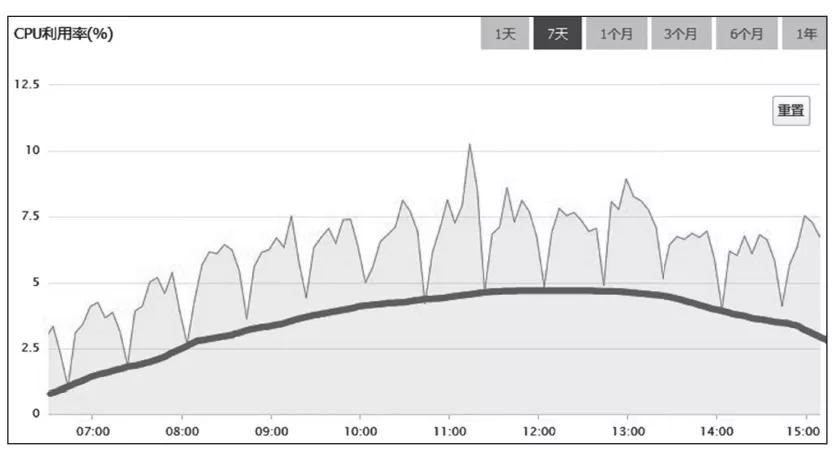
图5 系统增加缓存后,MySQL服务器各时段的CPU利用率(附带参考线)
排查整个系统,并未发现有以20分钟为周期的定时任务,继续扩大排查范围,排查周期小于20分钟的定时任务,最后终于定位到了问题所在。
该公司App的首页聚合了大量的内容,比如,精选商品、标题图、排行榜、编辑推荐,等等。这些内容会涉及大量的数据库查询操作。该系统在设计之初,为首页做了一个整体的缓存,缓存的过期时间是10分钟。但是随着需求的不断变化,首页上需要查询的内容越来越多,导致查询首页的全部内容变得越来越慢。
通过检查日志可以发现,刷新一次缓存的时间竟然长达15分钟。缓存是每隔10分钟整点刷新一次,因为10分钟内刷不完,所以下次刷新就推迟到了20分钟之后,这就导致了图5中,参考线以上每20分钟一个周期的规律波形。由于缓存的刷新比较慢,导致很多请求无法命中缓存,因此大量请求只能穿透缓存直接查询数据库。图9-5中参考线以下的部分,包含了很多这类请求占用的CPU利用率。
找到了问题的原因所在,下面就来进行针对性的优化,问题很快就得到了解决。新版本上线之后,再也没有出现过“午夜宕机”的问题。如
图6所示,对比优化前后MySQL服务器的CPU利用率,可以看出,优化的效果非常明显。
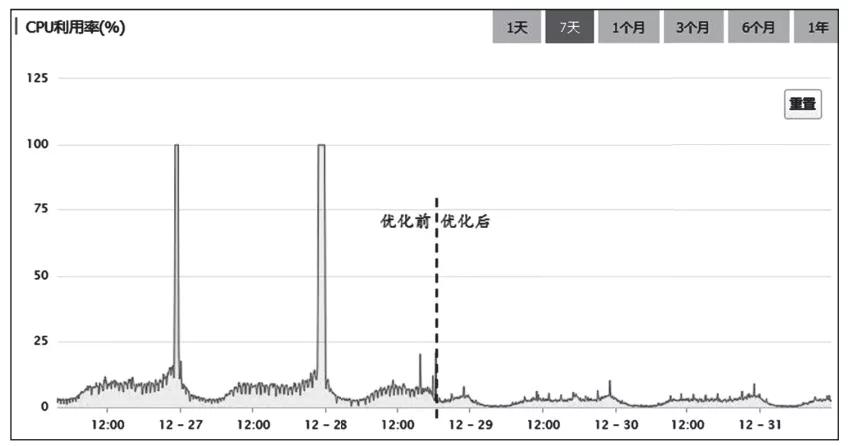
图6 优化前后MySQL服务器的CPU利用率对比
02如何避免悲剧重演
至此,导致问题的原因找到了,问题也得到了圆满解决。单从这个案例来看,问题的原因在于,开发人员在编写SQL时,没有考虑数据量和执行时间,缓存的使用也不合理。最终导致在访问高峰期时,MySQL服务器被大量的查询请求卡死,而无法提供服务。
作为系统的开发人员,对于上述问题,我们可以总结出如下两点经验。
第一,在编写SQL的时候,一定要小心谨慎、仔细评估,首先思考如下三个问题。
- SQL所涉及的表,其数据规模是多少?
- SQL可能会遍历的数据量是多少?
- 如何尽量避免写出慢SQL?
第二,能不能利用缓存减少数据库查询的次数?在使用缓存的时候,我们需要特别注意缓存命中率,应尽量避免请求因为命中不了缓存,而直接穿透到数据库上。
不过,我们无法保证,整个团队的所有开发人员以后都不会再犯这类错误。但是,这并不意味着,上述问题就无法避免了,否则大企业的服务系统会因为每天上线大量的BUG而无法正常工作。实际情况是,大企业的系统通常都是比较稳定的,基本上不会出现全站无法访问的问题,这要归功于其优秀的系统架构。优秀的系统架构,可以在一定程度上,减轻故障对系统的影响。
针对这次事故,我在系统架构层面,为该公司提了两条改进的建议。
第一条建议是,上线一个定时监控和杀掉慢SQL的脚本。这个脚本每分钟执行一次,检测在上一分钟内,有没有执行时间超过一分钟(这个阈值可以根据实际情况进行调整)的慢SQL,如果发现,就直接杀掉这个会话。
这样可以有效地避免因为一个慢SQL而拖垮整个数据库的悲剧。即使出现慢SQL,数据库也可以在至多1分钟内自动恢复,从而避免出现数据库长时间不可用的问题。不过,这样做也是有代价的,可能会导致某些功能,之前运行是正常的,在这个脚本上线后却出现了问题。但是,总体来说,这个代价还是值得付出的,同时也可以反过来督促开发人员,使其更加小心谨慎,避免写出慢SQL。
第二条建议是,将首面做成一个简单的静态页面,作为降级方案,首页上只要包含商品搜索栏、大的品类和其他顶级功能模块入口的链接就可以了。在Nginx上实现一个策略,如果请求首页数据超时,则直接返回这个静态页面的首页作为替代。后续即使首页再出现任何故障,也可以暂时降级,用静态首页替代,至少不会影响到用户使用其他功能。
这两条改进建议的实施都是非常容易的,不需要对系统进行很大的改造,而且效果也是立竿见影的。
当然,这个系统的存储架构还有很多可以改进的地方,比如,对数据做适当的隔离,改进缓存置换策略,将数据库升级为主从部署,把非业务请求的数据库查询迁移到单独的从库上,等等,只是这些改进都需要对系统做出比较大的改动升级,需要从长计议之后再在系统后续的迭代过程中逐步实施。
03小结
本文分析了一个由于慢SQL导致网站服务器访问故障的案例。在“破案”的过程中,我分享了一些很有用的经验,这些经验对于大家在工作中遇到类似问题时会有很大的参考作用。下面再来梳理一下这些经验。
1)根据故障时段出现在系统繁忙时这一现象,推断出故障原因与支持用户访问的功能有关。
2)根据系统能在流量峰值过后自动恢复这一现象,排除后台服务被大量请求冲垮的可能性。
3)根据服务器的CPU利用率曲线的规律变化,推断出故障原因可能与定时任务有关。
在故障复盘阶段,我们针对故障问题本身的原因,做了针对性的预防和改进,除此之外,更重要的是,在系统架构层面也进行了改进,整个系统变得更加健壮,不至于因为某个小的失误,就导致出现全站无法访问的问题。
我为该系统提出的第一个建议是定时自动杀死慢SQL,原因是:系统的关键部分要有自我保护机制,以避免因为外部的错误而影响到系统的关键部分。第二个建议是首页降级,原因是:当关键系统出现故障的时候,要有临时的降级方案,以尽量减少故障造成的不良影响。
这些架构上的改进措施,虽然不能完全避免故障,但是可以在很大程度上减小故障的影响范围,减轻故障带来的损失,希望大家能够仔细体会,活学活用。
关于作者:李玥,美团基础技术部高级技术专家,极客时间《后端存储实战课》《消息队列高手课》等专栏作者。曾在当当网、京东零售等公司任职。从事互联网电商行业基础架构领域的架构设计和研发工作多年,曾多次参与双十一和618电商大促。专注于分布式存储、云原生架构下的服务治理、分布式消息和实时计算等技术领域,致力于推进基础架构技术的创新与开源。
本文摘编自《电商存储系统实战:架构设计与海量数据处理》,经出版方授权发布。(ISBN:9787111697411)转载请保留文章出处。