Spark查询太慢?试试这款 Mpp 数据库吧!,

一、Greenplum数据库架构
Greenplum数据库是典型的主从架构,一个Greenplum集群通常由一个Master节点、一个Standby Master节点以及多个Segment实例组成,节点之间通过高速网络互连,如下图所示。Standby Master节点为Master节点提供高可用支持,Mirror Segment实例为Segment实例提供高可用支持。当Master节点出现故障时,数据库管理系统可以快速切换到Standby Master节点继续提供服务。
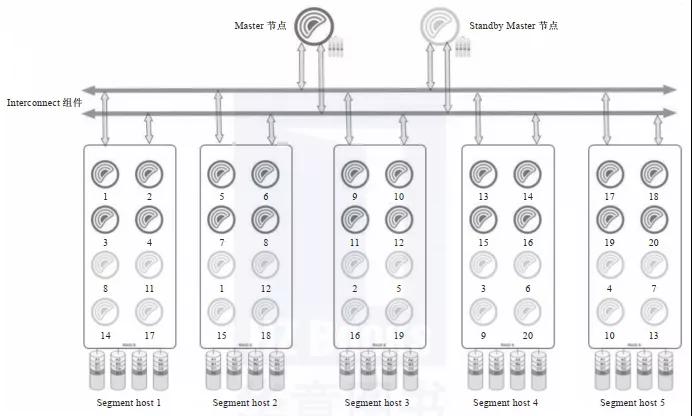
从软件的角度看,Greenplum数据库由Master节点、Segment实例和Interconnect组件三部分组成,各个功能模块在系统中承载不同的角色。
Master节点是Greenplum数据库的主节点,也是数据库的入口,主要负责接收用户的SQL请求,将其生成并行查询计划并优化,然后将查询计划分配给所有的Segment实例进行处理,协调集群的各个Segment实例按照查询计划一步一步地并行处理,最后获取Segment实例的计算结果并汇总后返回给客户端。
从用户的角度看Greenplum集群,看到的只是Master节点,无须关心集群内部机制,所有的并行处理都是在Master节点控制下自动完成的。Master节点一般只存储系统数据,不存储用户数据。为了提高系统可用性,我们通常会在Greenplum集群的最后一个数据节点上增加一个Standby Master节点。
Segment是Greenplum实际存储数据和进行数据读取计算的节点,每个Segment都可以视为一个独立的PostgreSQL实例,上面存放着一部分用户数据,同时参与SQL执行工作。Greenplum Datanode通常是指Segment实例所在的主机,用户可以根据Datanode的CPU数、内存大小、网络宽带等来确定其上面的Segment实例个数。官方建议一个Datanode上面部署2~8个Segment实例。Segment实例越多,单个实例上面的数据越少(平均分配的情况下),单个Datanode的资源使用越充分,查询执行速度就越快。Datanode服务器的数量根据集群的数据量来确定,最大可以支持上千台。另外,为了提高数据的安全性,我们有时候会在生产环境中创建Mirror Segment实例作为备份镜像。
Interconnect是Master节点与Segment实例、Segment实例与Segment实例之间进行数据传输的组件,它基于千兆交换机或者万兆交换机实现数据在节点之间的高速传输。默认情况下,Interconnect组件使用UDP在集群网络节点之间传输数据,因为UDP无法保证服务质量,所以Interconnect组件在应用层实现了数据包验证功能,从而达到和TCP一样的可靠性。
Greenplum执行查询语句的过程如下:当GP Server收到用户发起的查询语句时,会对查询语句进行编译、优化等操作,生成并行执行计划,分发给Segment实例执行;Segment实例通过Interconnect组件和Master节点、其他Segment实例交换数据,然后执行查询语句,执行完毕后,会将数据发回给Master节点,最后Master节点汇总返回的数据并将其反馈给查询终端。
二、Greenplum的优势
首先,与传统数据库相比,Greenplum作为分布式数据库,本身具有高性能优势。对各行各业来说,OLTP系统最重要的是在保证ACID事务管理属性的前提下满足业务的并发需求,对于大多数非核心应用场景,MySQL、SQL Server、DB2、Oracle都可以满足系统要求,并且随着MySQL性能的优化和云原生数据库的发展,基于MySQL或者PostgreSQL商业化的数据库会越来越普及。数据中台的定位是一个OLAP系统,上述数据库就很难满足海量数据并发查询的要求了。上述数据库的横向扩展能力有限,并且软硬件成本高昂,不适合作为OLAP系统的数据库。Greenplum作为一款基于MPP架构的数据库,具有开源、易于扩展、高查询性能的特点,性价比碾压DB2、Oracle、Teradata等传统数据库。
其次,Greenplum作为分布式数据库,和同为分布式数据库的Hive相比,优势也非常明显。早期Hadoop的无模式数据已经让开发者饱受痛苦,后面兴起的Hive、Presto、Spark SQL虽然支持简单的SQL,但是查询性能仍然是分钟级别的,很难满足OLAP的实时分析需求。后期虽有Impala+Kudu,但是查询性能仍然弱于同为MPP架构的Greenplum。除此之外,Hadoop生态圈非常复杂,安装和维护的工作量都很大,没有专业的运维团队很难支撑系统运行。而Greenplum支持的SQL标准最全面,查询性能在毫秒级,不仅能很好地支持数据ETL处理和OLAP查询,还支持增删改等操作,是一款综合实力非常强的数据库。相对于Hadoop多个组件组成的庞大系统,Greenplum数据库在易用性、可靠性、稳定性、开发效率等方面都有非常明显的优势。
最后,Greenplum作为MPP数据库中的一员,相对于其他MPP架构数据库,也具有非常明显的优势。Greenplum研发历史长、应用范围广、开源稳定、生态系统完善。生态系统完善是指Greenplum的工具箱非常多:GPload可满足高速加载需求,PXF可满足外置表和文件存储需求,MADlib可满足数据挖掘需求,GPCC可满足系统监控运维需求。相对于TiDB、TBase、GaussDB等新兴数据库来说,Greenplum的应用案例最多,生态系统最完善,并且Bug更少。同时,TiDB、TBase、GaussDB等数据库都定位于优先满足OLTP的同时提高OLAP的性能,而Greenplum是以OLAP优先的。虽然前者也有优势,但是将OLAP和OLTP合并实现起来存在以下困难:数据分布在不同的系统已经是行业现实,没有办法将数据集中到同一个数据库;数据中台天然就是一个OLAP系统,没有办法按照OLTP模式设计。综上,作为分布式关系型数据库,Greenplum是搭建数据中台的首选数据库。
如下图是阿里巴巴大数据平台进化历程。2010年前后,阿里巴巴曾经使用Greenplum来替换Oracle集群,将其作为数据分析平台。从数量上说,Greenplum在2010年实现了Oracle 10倍数据量的管理,即1000TB。但Oracle的架构这些年没有太大变化,而Greenplum数据库已有翻天覆地的革新。在阿里巴巴应用的时代,Greenplum还是EMC旗下的商用数据库,平台尚在发育期,功能也不太完善。而如今的Greenplum已经是社区开源的产品,内核PostgreSQL也已完成了多个版本的升级迭代,现在更是轻轻松松支持上千台服务器的集群,因此承载PB级的数据自不在话下。
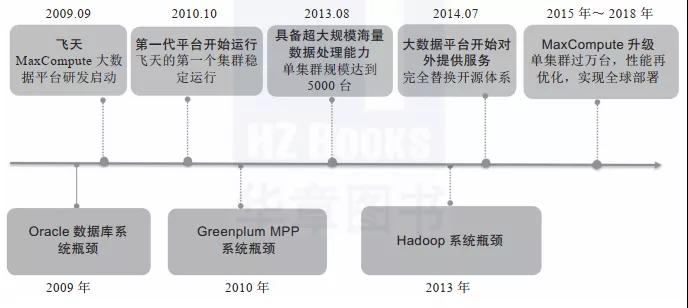
对于大多数有构建数据中台需求的企业,1000TB已经是一个无法企及的高度。大多数据企业的数据都在数TB到100TB的范围内,这个规模的数据正是Greenplum的主要战场。100TB以下规模的数据仓库或者数据中台,Hive发挥不了架构上的优势,反而影响开发速度和运维工作,实在是得不偿失。
在查询性能方面,Greenplum自然不是第一,虽然业界尚无定论,但是据笔者了解,目前ClickHouse是当之无愧的OLAP冠军。相对于ClickHouse,Greenplum胜在高性能的GPload插件、强大的ETL功能、不算太弱的增删改性能。目前,数据中台在稳步向实时流处理迈进,由于不擅长单条更新和删除,因此ClickHouse只适合执行离线数据查询任务,可以作为超大规模数据中台的OLAP查询引擎。
综上所述,虽然Greenplum某些方面不是最优秀的,但仍是最适合搭建数据中台的分布式数据平台,并且以Greenplum现有的性能和管理的数据规模,可以满足绝大多数中小企业的数据中台需求。
三、Greenplum性能测试
gpcheckperf是Greenplum数据库自带的性能测试工具,在指定的主机上启动会话并进行以下性能测试。
1)磁盘I/O测试(dd测试):测试逻辑磁盘或文件系统的顺序吞吐性能,该工具使用dd命令。dd命令是一个标准的UNIX工具,记录了在磁盘上读写一个大文件需要花费的时间,以MB/s为单位计算磁盘I/O性能。默认情况下,用于测试的文件尺寸按照主机上随机访问内存(RAM)的两倍计算。这样确保了测试是真正地测试磁盘I/O而不是使用内存缓存。
2)内存带宽测试:为了测试内存带宽,该工具使用STREAM基准程序来测量可持续的内存带宽(以MB/s为单位)。本项测试内容是检验操作系统在不涉及CPU计算性能的情况下是否受系统内存带宽的限制。在数据集较大的应用程序中(如在Greenplum数据库中),低内存带宽是一个主要的性能问题。如果内存带宽明显低于CPU的理论带宽,则会导致CPU花费大量的时间等待数据从系统内存传递过来。
3)网络性能测试:为了测试网络性能以及Greenplum数据库Interconnect组件的性能,该工具运行一种网络基准测试程序,该程序在当前主机连续发送5s的数据流到测试包含的每台远程主机上。数据被并行传输到每台远程主机,并以MB/s为单位,分别报告最小、最大、平均和中位网络传输速率。如果汇总的传输速率比预期慢(小于100MB/s),可以使用-r N选项串行运行该网络测试以获取每台主机的结果。要运行全矩阵带宽测试,用户可以指定-r M选项,这将导致每台主机都发送和接收来自指定的其他主机的数据。该测试适用于验证交换结构是否可以承受全矩阵负载。
gpcheckperf命令应用举例如下。
- #使用/data1和/data2作为测试目录在文件host_file中的所有主机上运行磁盘I/O和内存带宽测试
- gpcheckperf -f hostfile_gpcheckperf -d /data1 -d /data2 -r ds
- #在名为sdw1和sdw2的主机上只使用测试目录/data1运行磁盘I/O测试。显示单个主机结果并以详细模式运行
- gpcheckperf -h sdw1 -h sdw2 -d /data1 -r d -D -v
- #使用测试目录/tmp运行并行网络测试,其中hostfile_gpcheck_ic*指定同一Interconnect子网内的所有网络接口的主机地址名称
- gpcheckperf -f hostfile_gpchecknet_ic1 -r N -d /tmp
- gpcheckperf -f hostfile_gpchecknet_ic2 -r N -d /tmp
性能测试时间通常较长,为了进行完整的测试,我一般会创建如下测试脚本,在后台执行性能测试任务。
- #创建如下shell脚本
- [gpadmin@gp-master ~]$ cat gpcheckperf-test.sh
- #!bin/bash
- echo "--------- start ----------- "
- a=`date +"%Y-%m-%d %H:%M:%S"`
- echo $a
- gpcheckperf -f /data/greenplum/greenplum-db/all_hosts -d /data/greenplum/ -v
- echo "------------- end ----------"
- b=`date +"%Y-%m-%d %H:%M:%S"`
- echo $b
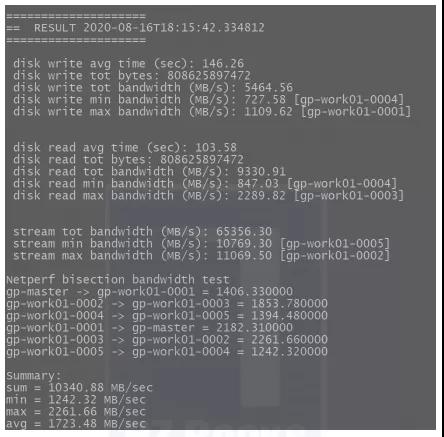
性能测试后台执行nohup sh gpcheckperf-test.sh &命令后,查看nohup.out的输出结果,如下图所示(每台服务器采用10块普通硬盘通过软件组成Raid 5)。
关于作者:王春波,资深架构师和数据仓库专家,现任上海启高信息科技有限公司大数据架构师,Apache Doris和openGauss贡献者,Greenplum中文社区参与者。 公众号“数据中台研习社”运营者。
本文摘编于《高效使用Greenplum:入门、进阶与数据中台》,经出版方授权发布。(书号:9787111696490)转载请保留文章来源。