Flink SQL 知其所以然之去重不仅仅有 Count Distinct 还有强大的 Deduplication,

1.序篇
源码公众号后台回复1.13.2 deduplication 的奇妙解析之路获取。
下面即是文章目录,也对应到了本文的结论,小伙伴可以先看结论快速了解博主期望本文能给小伙伴们带来什么帮助:
- 背景及应用场景介绍:博主期望你了解到,flink sql 的 deduplication 其实就是 row_number = 1,所以它可以在去重的同时,还能保留原始字段数据
- 来一个实战案例:博主以一个日志上报重复的场景,来引出下文要介绍的 flink sql deduplication 解决方案
- 基于 Deduplication 的解决方案及原理解析:博主期望你了解到,deduplication 中,当 row_number order by proctime(处理时间)去重的原理就是给每一个 partition key 维护一个 value state。如果当前 value state 不为空,则说明 id 已经来过了,当前这条数据就不用下发了。如果 value state 为空,则 id 还没还没来过,把 value state 标记之后,把当前数据下发。
- 总结及展望篇
2.背景及应用场景介绍
你是否遇到过一下的场景:
由于上游发过来的数据有重复或者日志源头数据有重复上报,导致下游计算 count,sum 时算多
想做到去重计算的同时,原始表的所有字段还能正常保留且下发
那么你能想到哪些解决方案呢?
熟悉离线计算的小伙伴可能很快就能给出答案。没错,hive sql 中的 row_number = 1。flink sql 中也是提供了一模一样的功能,xdm,完美的解决这个问题。
下面开始正式篇章。
3.来一个实战案例
先来一个实际案例来看看在具体输入值的场景下,输出值应该长啥样。
场景:埋点数据上报的的字段有 id(标识唯一一条日志),timestamp(事件时间戳),page(时间发生的当前页面),param1,param2,paramN...。但是日志上报时由于一些机制导致日志上报重复,下游算多了,因此需要做一次去重,下游再去消费去过重的数据。
来一波输入数据:
| id | timestamp | page | param1 | param2 | paramN |
|---|---|---|---|---|---|
| 1 | 2021-11-01 00:01:00 | A | xxx1 | xxx2 | xxxN |
| 1 | 2021-11-01 00:01:00 | A | xxx1 | xxx2 | xxxN |
| 2 | 2021-11-01 00:01:00 | A | xxx3 | xxx2 | xxxN |
| 2 | 2021-11-01 00:01:00 | A | xxx3 | xxx2 | xxxN |
| 3 | 2021-11-01 00:03:00 | C | xxx5 | xxx2 | xxxN |
其中第二条和第四条是重复上报的数据,则预期输出数据如下:
| id | timestamp | page | param1 | param2 | paramN |
|---|---|---|---|---|---|
| 1 | 2021-11-01 00:01:00 | A | xxx1 | xxx2 | xxxN |
| 2 | 2021-11-01 00:01:00 | A | xxx3 | xxx2 | xxxN |
| 3 | 2021-11-01 00:03:00 | C | xxx5 | xxx2 | xxxN |
4.基于 Deduplication 的解决方案及原理解析
4.1.sql 写法
还是上面的案例,我们来看看最终的 sql 应该怎么写:
- select id,
- timestamp,
- page,
- param1,
- param2,
- paramN
- from (
- SELECT
- id,
- timestamp,
- page,
- param1,
- param2,
- paramN
- -- proctime 代表处理时间即 source 表中的 PROCTIME()
- row_number() over(partition by id order by proctime) as rn
- FROM source_table
- )
- where rn = 1
上面的 sql 应该很好理解。其中由于我们并不关心重复数据上报的时间前后,所以此处就直接使用 order by proctime 进行处理,按照数据来的前后时间去第一条。
4.2.proctime 下 flink 生成的算子图及 sql 算子语义
算子图如下所示:
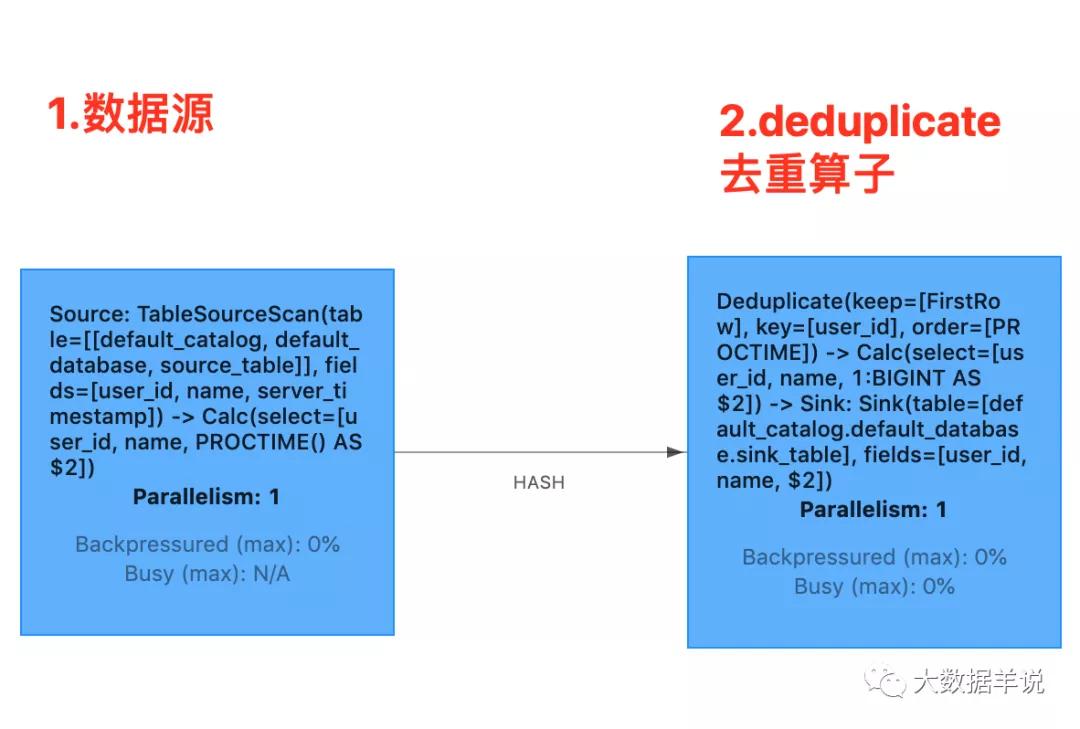
deduplication
- source 算子:source 通过 keyby 的方式向 deduplication 算子发数据时,其中 keyby 的 key 就是 sql 中的 id
- deduplication 算子:deduplication 算子为每一个 partition key 都维护了一个 value state 用于去重。每来一条数据时都从当前 partition key 的 value state 去获取 value, 如果不为空,则说明已经有数据来过了,当前这一条数据就是重复数据,就不往下游算子下发了, 如果为空,则说明之前没有数据来过,当前这一条数据就是第一条数据,则把当前的 value state 值设置为 true,往下游算子下发数据
4.3.proctime 下 deduplication 原理解析
具体的去重算子为 deduplication。我们通过 transformation 可以看到去重算子为下图所示:
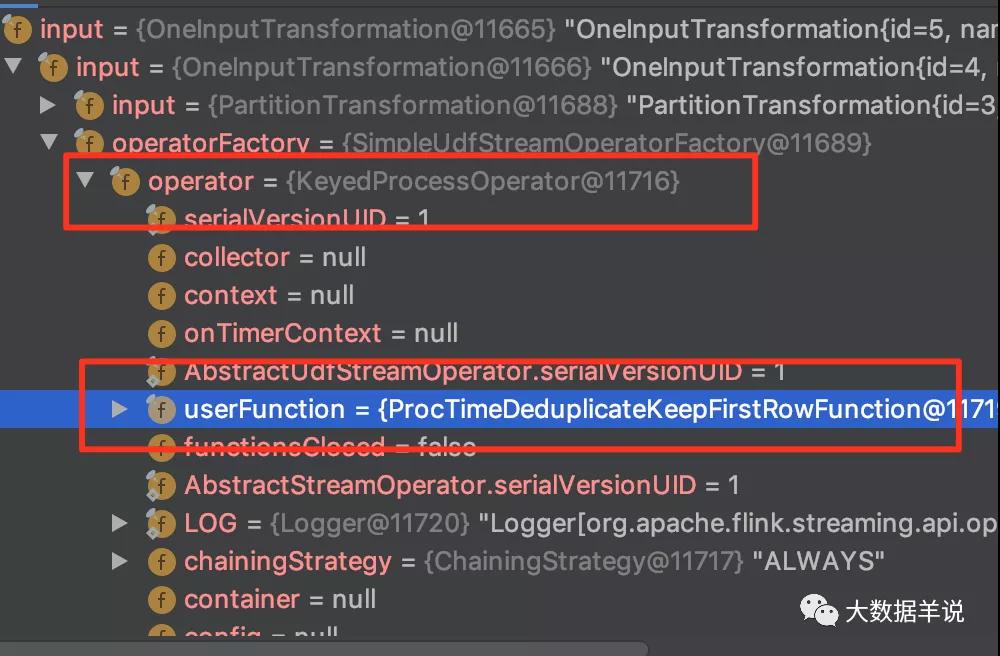
transformation
上述的去重逻辑集中在 org.apache.flink.table.runtime.operators.deduplicate.ProcTimeDeduplicateKeepFirstRowFunction 的 processFirstRowOnProcTime,如下图所示:
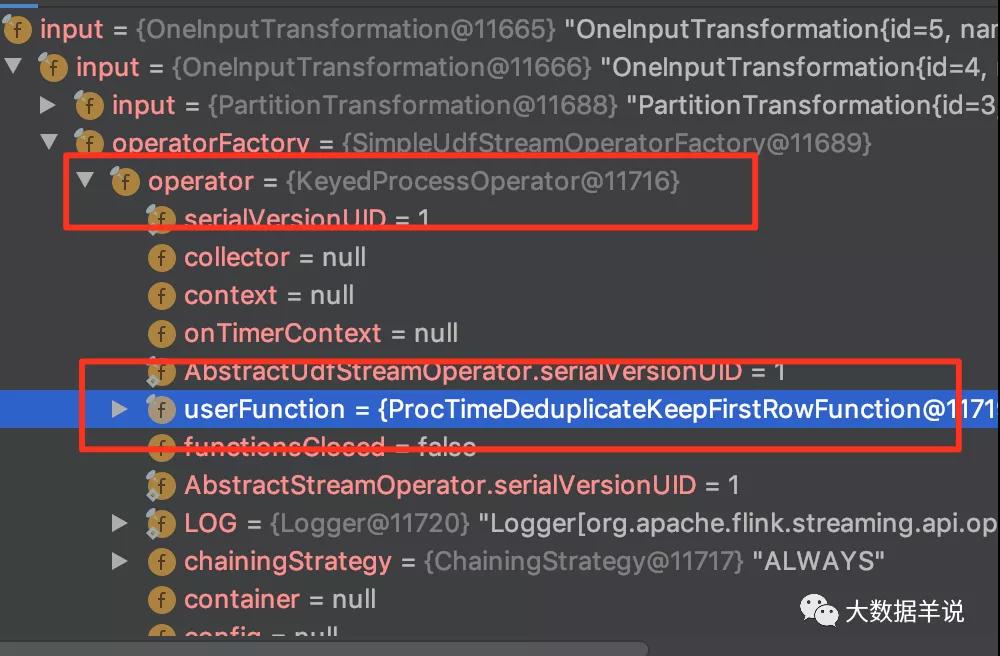
ProcTimeDeduplicateKeepFirstRowFunction
5.总结与展望
源码公众号后台回复1.13.2 deduplication 的奇妙解析之路获取。
本文主要介绍了 deduplication 的应用场景案例以及其运行原理,主要包含下面两部分:
背景及应用场景介绍:博主期望你了解到,flink sql 的 deduplication 其实就是 row_number = 1,所以它可以在去重的同时,还能保留原始字段数据
来一个实战案例:博主以一个日志上报重复的场景,来引出下文要介绍的 flink sql deduplication 解决方案
基于 Deduplication 的解决方案及原理解析:博主期望你了解到,deduplication 中,当 row_number order by proctime(处理时间)去重的原理就是给每一个 partition key 维护一个 value state。如果当前 value state 不为空,则说明 id 已经来过了,当前这条数据就不用下发了。如果 value state 为空,则 id 还没还没来过,把 value state 标记之后,把当前数据下发。