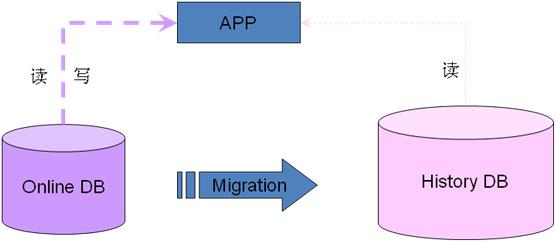
6.2.1 实时数据历史数据的拆分
和历史数据迁移是一样的逻辑,就是要将online库的数据迁移到listory的数据库里面,对于实时的读写来说,数据是放在online db库里面,对于时间较远的数据来说,是放在历史History DB记录库里面的,这里的历史库可以是mysql也可以是别的nosql库等。
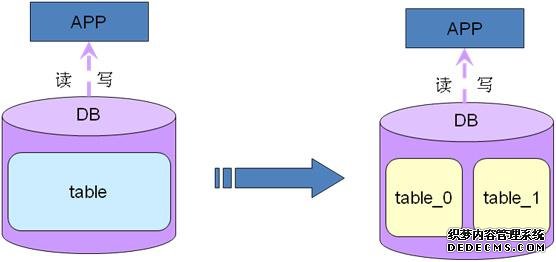
6.2.2 单库多表拆分
主要不是解决容量问题,而是解决性能问题而扩展的,加入当前实例只有一个DB,有一个大表,一个大表就把整个实例占满了,这个时候就不能拆分db了,因为只有一个单表,这个时候我们就只能拆表了,拆表的方式主要是解决性能问题,因为单个表越大,对于mysql来说遍历表的树形结构遍历数据会消耗更多的资源,有时候一个简单的查询就可能会引起整个db的很多叶子节点都要变动。表的insert、update、delete操作都会引起几乎所有节点的变更,此时操作量会非常大,操作的时候读写性能都会很低,这个时候我们就可以考虑把大表拆分成多个小表,工作经历中是按照hash取模打散成16个小表,也有按照id主键/50 取模打散到50个小表当中,下图实例是打散成2个小表。
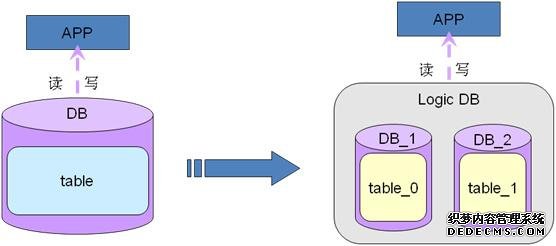
6.2.3 多库多表拆分
在单库多表的基础上,如果单库空间资源已经不足以提供业务支撑的话,可以考虑多库多表的方式来做,解决了空间问题和性能问题,不过会有一个问题就是跨库查询操作,查询就会有另外的策略,比如说加一个logic db层来实现跨库跨实例自动查询,简单如下图所示:
6.2.4水平拆分小结
水平拆分原则:
– a. 尽量均匀的拆分维度。
– b. 尽量避免跨库事务。
– c. 尽量避免跨库查询。
设计:
–a根据拆分维度,做mod进行数据表拆分,大部分都是取模的拆分机制,比如hash的16模原则等。
–b根据数据容量,划分数据库拆分
数据操作
–a跨事务操作:分布式事务,通过预写日志的方式来间接地实现。
–b跨库查询:数据汇总or消息服务
6.2.5 案例说明
u 案例:
– 按照用户维度进行拆分成64个分库,1024个分表
- user_id%1024 拆分到1024张分表中
- 每个分库中存放1024/64张分表
- 取模的时候,可以用id的最后4位数据或者3位数字来取模就可以了。
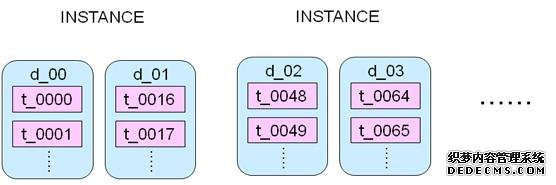
u 操作1:采用Configure DB
– 拆分之后的查询操作,做一个Configure DB,这个DB存放的是所有实例的库表的映射关系,当我APP发来有一个请求查询user1的数据,那么这个user1的数据是存放在上千个实例中的哪一个库表呢?这个关联信息就在Configure DB里面,APP先去Configure DB里面取得user1的关联系信息(比如是存放在d_01库上的t_0016表里面),然后APP根据关联信息直接去查询对应的d_01实例的 t_0016表里面取得数据。

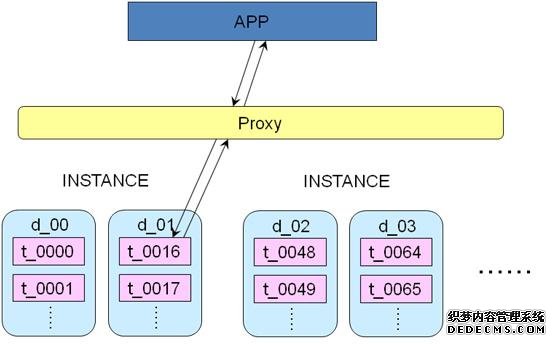
u 操作2:采用Proxy
– 拆分之后的查询操作,做一个Proxy,APP访问Proxy,Proxy根据访问规则就可以直接路由到具体的db实例,生成新的sql去操作对应的db实例,然后通过Proxy协议进行操作把操作结果返回给APP。
– 优势是Proxy和db实例是在一个网段,这样Proxy与db实例的操作的时间是非常短的。
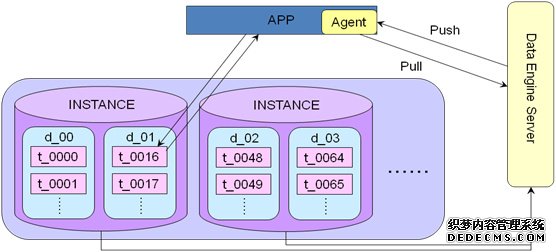
u 操作3:采用Data Engine
– 拆分之后的查询操作,有一个Data Engine Service,这个DES里面配置了所有数据库实例的映射关系,需要在APP应用端安装一个Agent,是同步逻辑,在JDBC层实现,DES可以实现读写分离,原理可以参考TDDL的实现。
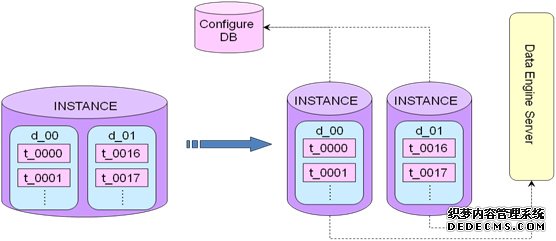
6.3 集群管理
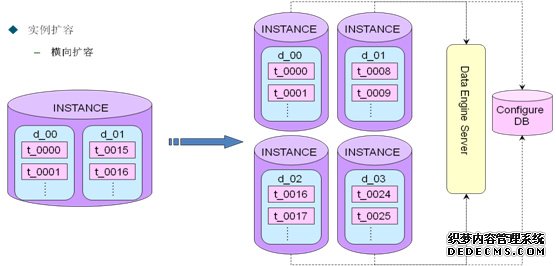
纵向扩容:一个实例拆分成多个实例,纵向拆分比较简单,修改的东西比较少,拆分的时候要通知到Configure DB或者DES,以免拆分之后查询不到数据或者数据录入不到新的db上面,如下图所示:
横向扩容:比较复杂,在纵向扩容成2个库的基础之上,再一次对库的表进行扩容,所以需要及时通知Configure DB和DES更细库和表的路由连接信息。