二:MySQL架构设计—常见架构
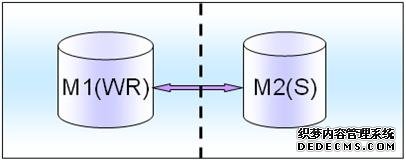
(1)强一致性
对读一致性的权衡,如果是对读写实时性要求非常高的话,就将读写都放在M1上面,M2只是作为standby,就是采取和上面的一(4)的读少写多的一样的架构模式。
比如,订单处理流程,那么对读需要强一致性,实时写实时读,类似这种涉及交易的或者动态实时报表统计的都要采用这种架构模式
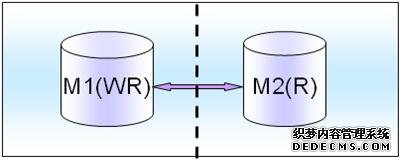
(2)弱一致性
如果是弱一致性的话,可以通过在M2上面分担一些读压力和流量,比如一些报表的读取以及静态配置数据的读取模块都可以放到M2上面。比如月统计报表,比如首页推荐商品业务实时性要求不是很高,完全可以采用这种弱一致性的设计架构模式。
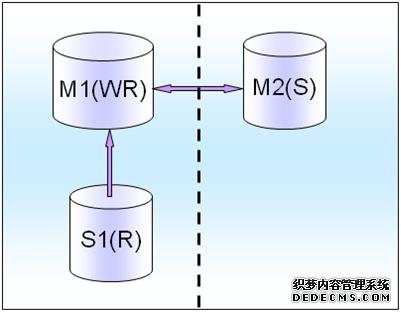
(3)中间一致性
如果既不是很强的一致性又不是很弱的一致性,那么我们就采取中间的策略,就是在同机房再部署一个S1(R),作为备库,提供读取服务,减少M1(WR)的压力,而另外一个idc机房的M2只做standby容灾方式的用途。
当然这里会用到3台数据库服务器,也许会增加采购压力,但是我们可以提供更好的对外数据服务的能力和途径,实际中尽可能两者兼顾。
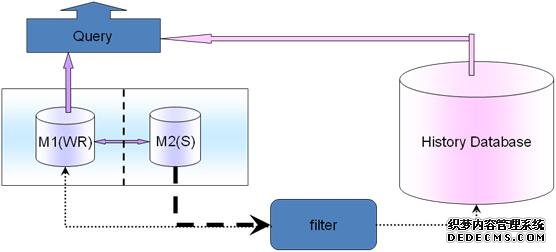
(4)统计业务
比如PV、UV操作、页数的统计、流量的统计、数据的汇总等等,都可以划归为统计类型的业务。
数据库上做大查询的统计是非常消耗资源的。统计分为实时的统计和非实时的统计,由于mysql主从是逻辑sql的模式,所以不能达到100%的实时,如果是online 要严格的非常实时的统计比如像火车票以及金融异地结算等的统计,mysql这块不是它的强项,就只有查询M1主库来实现了。
A,但是对于不是严格的实时性的统计,mysql有个很好的机制是binlog,我们可以通过binlog进行解析Parser,解析出来写入统计表进行统计或者发消息给应用端程序来进行统计。这种是准实时的统计操作,有一定的短暂的可接受的统计延迟现象,如果要100%实时性统计只有查询M1主库了。
通过 binlog的方式实现统计,在互联网行业,尤其是电商和游戏这块,差不多可以解决90%以上的统计业务。有时候如果用户或者客户提出要实时read- time了,大家可以沟通一下为什么需要实时,了解具体的业务场景,有些可能真的不需要实时统计,需要有所权衡,需要跟用户和客户多次有效沟通,做出比较适合业务的统计架构模型。
B,还有一种offline统计业务,比如月份报表年报表统计等,这种完全可以把数据放到数据仓库里面或者第三方Nosql里面进行统计。

(5)历史数据迁移
历史数据迁移,需要尽量不影响现在线上的业务,尽量不影响现在线上的查询写入操作,为什么要做历史数据迁移?因为有些业务的数据是有时效性的,比如电商中的已经完成的历史订单等,不会再有更新操作了,只有很简单的查询操作,而且查询也不会很频繁,甚至可能一天都不会查询一次。
如果这时候历史数据还在online库里面或者online表里面,那么就会影响online的性能,所以对于这种,可以把数据迁移到新的历史数据库上,这个历史数据库可以是mysql也可以是nosql,也可以是数据仓库甚至hbase大数据等。
实现途径是通过 slave库查询出所有的数据,然后根据业务规则比如时间、某一个纬度等过滤筛选出数据,放入历史数据库(History Databases)里面。迁移完了,再回到主库M1上,删除掉这些历史数据。这样在业务层面,查询就要兼顾现在实时数据和历史数据,可以在filter 上面根据迁移规则把online查询和history查询对接起来。比如说一个月之内的在online库查询一个月之前的在history库查询,可以把这个规则放在DB的迁移filter层和应用查询业务模块层。如果可以的话,还可以配置更细化,通过应用查询业务模块层来影响DB的迁移filter层,比如以前查询分为一个月为基准,现在查询业务变化了,以15天为基准,那么应用查询业务模块层变化会自动让DB的filter层也变化,实现半个自动化,更加智能一些。