CoolHash数据库引擎压测对比报告(1)
Coolhash当前性能指标:读写吞吐量超过百万,千万级别查询1秒完成,连续48小时打满CPU强压力运行稳定。redis官方公布读写性能在10万tps,leveldb官方公布写性能在40万tps,读在6万tps,redis和leveldb都是倾向k/v高速读写,但不具备高效检索功能,没有join关联设计。coolhash可以拿去pk世界上任何的数据库引擎产品。
下面以redis为例进行了详细测试和技术分析,leveldb的性能可详见其官方资料,在写性能上优于redis,但是读性能和多数据结构支持上不如redis,leveldb读代价高是因为需要在内存以及各级数据文件逐项查找并要优先考虑数据最新状态,另外redis还提供server和集群功能,leveldb不提供,redis是内存方式+内存快照持久化,而leveldb是Memtable+硬盘持久化,leveldb持久化不受内存限制,也做到了接近缓存的性能,未来k/v数据库的趋势最好能直接当作缓存使用,并能支持高效检索功能。
按照redis的常用方式,我们在一台服务器上进行redis“单server”和“多server”的测试:

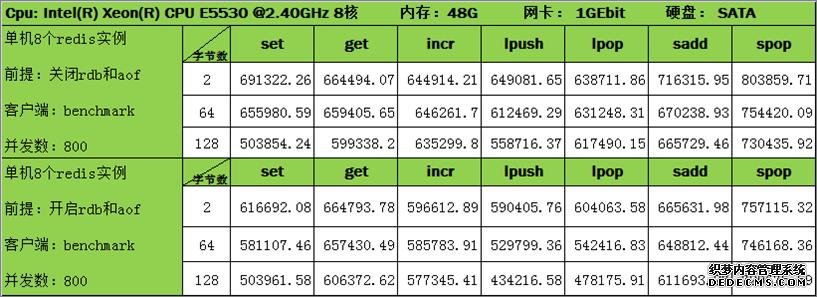
从上面两个图,我们可以看到:
-
redis是一个单进程单线程的实现,单server的读写TPS大概在8—12万跟redis官网公布的数据一致),为了充分利用能够资源,redis官方建议一台机器部署多个redis server。
-
上面第二个图的TPS超过了8-12万的限制,这实际上是在一台服务器上部署了多个redis server,并将该服务器总的吞吐量算到一个redis server上得到的。但是写的时候是客户端各自写不同的redis server,多个redis server之间的数据是彼此独立的,在不同的内存空间中,如果分开计算每个redis server的写入总量除以时间,TPS还是在8-12万左右。
我们再到24核/256g/SATA硬盘的pc server上测试一下redis的benchmark,200个客户端共写入2000万数据,发现性能变化不大,还是在10万左右的TPS,又测试了20个客户端写入2000万数据,12万TPS:
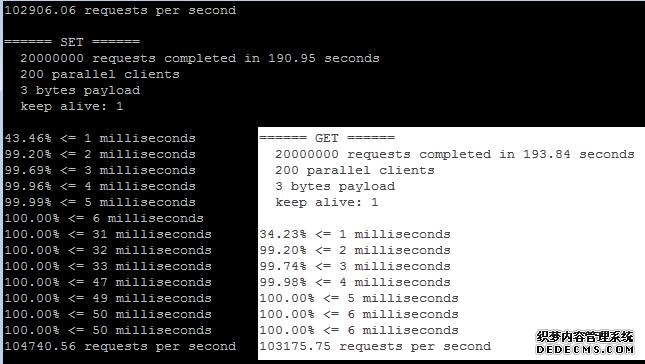
Redis很优秀,但是也有一些局限:
-
redis不是一个并行数据库,由单进程单线程实现,已经做到了单进程极限,性能很难再突破。如果要重新改写redis,代价很大,而且只有redis作者有能力做,其他外围的捐献者动不了。redis官方采取一种曲线救国方式,不改变单进程模式,采取外围做集群,部署多个server来提高CPU利用率,redis3.0的集群方案使用一种hash slot算法不是一致哈希),用多个redis server做数据分片存储,按照crc16/16384取模方式,让客户端根据hash slot的配置寻址,扩容按照slot单位做数据迁移达到负载均衡。由于在同台服务器也存在多server实例集群,会牵扯出很多server的master-slave复制和数据迁移一致性等复杂性,也容易引起后端的IO争用,特别是在AOF模式时。
-
redis是一种内存快照方式,也就意味着它的持久化大小受内存限制,不是真正的数据库持久化存储,内存是昂贵的,为了扩大内存存储,往往需要更多的服务器搭建缓存集群,redis作者曾想增加一种diskstore的全持久化+cache方式,采用SHA1算法来建立存储结构,来改进内存快照方式的种种不足,但是涉及到对redis底层持久化方式的重构,这个计划从11年提出,截至到目前3.0版本,仍然还没有提供。
-
redis的存储方式不是按照数据库存储索引结构设计,无法做到高性能的按范围、按key/value的模糊检索,更多只能在内存中进行全局数据的遍历过滤,没有高效的查询功能,redis更适合做缓存读写,不适合当作数据库存储使用。
国内的redis使用团队更多也是在运维工具、监控管理、主备、故障恢复等等方面改进,不具备对上面redis的3点内核局限的重构能力。
我们接下来在同机环境24核/256g/SATA硬盘)测试coolhash,实际上coolhash也可以像上面redis那样在一台服务器上部署多个server实例,但是我们这里启动一个coolhash就够了。coolhash是一个并行数据库引擎和数据库server,可以通过调整“coolhash数据工人数量、客户端并发数量、每客户端读写数量”三个指标项达到一台服务器的最佳吞吐量性能。
coolhash通过一组数据工人并行的完成任务,我们先测试一个coolhash启动多少个数据工人最合适,下面在一台服务器上运行coolhash并分别启动1-96个工人,再用另外一台服务器模拟了200个客户端并发,每个客户端写入10万数据,累计2000万数据,数据格式key=n(0<n<2000万),value=n(0<n<2000万),平均大小在几十字节左右,比上面redis的benchmark的每条数据3字节要大,客户端和服务器在同一个局域网内,通过IP访问。注意:不要简单的在一个jvm里以多线程模拟并发,如果客户端包存在公共变量,容易引起混乱,应该启动200个独立客户端)
测试1:x个数据工人,200个客户端并发,每个客户端写入10万数据
| 数据工人 | 1个工人 | 8个工人 | 24个工人 | 32个工人 | 96个工人 |
| 耗时 | 400秒 | 40秒 | 20秒 | 23秒 | 25秒 |
| cpu最高峰 | 10% | 20% | 75% | 85% | 90% |
| TPS | 5万/秒 | 50万/秒 | 100万/秒 | 87万/秒 | 80万/秒 |
分析:可以清晰的看到并行数据库的优势明显,如果只有一个数据工人,也就是单进程模式,它的TPS是很难超出10万的,如果是8个数据工人并行作业,性能一下子就能从400秒减少到40秒,提升10倍,但也不是数据工人越多性能越好,我们看到24-32个工人是个顶峰,如果再增加工人数虽然能提升cpu使用率,但是调度开销大,后端硬盘io等跟不上,导致性能反而有所下降。
根据上面的结论,我们配置coolhash启动24个数据工人最合适,接下来再进一步调整“客户端并发数”和“每个客户端写入数量”,来达到一台服务器的最佳性能。
测试2:24个数据工人,x个客户端并发,每个客户端写入10万数据
| 客户端数 | 1并发 | 10并发 | 20并发 | 50并发 | 100并发 | 200并发 |
| 写入总量 | 10万 | 100万 | 200万 | 500万 | 1000万 | 2000万 |
| 耗时 | 1秒 | 3秒 | 5秒 | 10秒 | 18秒 | 20秒 |
| TPS | 10万/秒 | 33万/秒 | 40万/秒 | 50万/秒 | 55万/秒 | 100万/秒 |
分析:如果每个客户端写相同数量的数据,随着并发数的提高,总体的吞吐量会高于单客户端呈线性增长趋势,但是受服务器cpu、内存、io等性能限制,不会一直增长,会倾向于一个平衡值。每台服务器并不是能承受无限大的并发数量,如果超出了承受限制,客户端会长时间等待,容易产生socket连接超时。合理的控制并发数量能提升服务器的吞吐性能,下面我们增大每个客户端的写入数量,减少总的并发数,并观察效果。
测试3:24个数据工人,20个客户端并发,每个客户端写入x万数据
| 每客户端写 | 10万/每 | 50万/每 | 100万/每 | 200万/每 | 300万/每 |
| 写入总量 | 200万 | 1000万 | 2000万 | 4000万 | 6000万 |
| 耗时 | 4秒 | 6秒 | 10秒 | 15秒 | 22秒 |
| 写TPS | 50万/秒 | 167万/秒 | 200万/秒 | 267万/秒 | 272万/秒 |
分析:可以看到同样写入2000万数据,采用20并发*100万比200并发*10万的性能提升了一倍,能达到200万以上TPS。这是因为客户端建立连接后,一次提交100万条数据的写入请求,相比每条数据连接server,能很大节省网络开销和硬盘IO开销。由此我们也能得到,并不是并发连接越多越好,而是控制一定数量的连接池性能会更好。
接下来我们再以使用相同参数,测试一下读的性能。
测试4:24个数据工人,20个客户端并发,每个客户端读出x万数据
| 每客户端读 | 10万/每 | 50万/每 | 100万/每 | 200万/每 | 300万/每 |
| 读出总量 | 200万 | 1000万 | 2000万 | 4000万 | 6000万 |
| 耗时 | 4秒 | 6秒 | 11秒 | 20秒 | 30秒 |
| 读TPS | 50万/秒 | 167万/秒 | 182万/秒 | 200万/秒 | 200万/秒 |
分析:coolhash是一个读写平衡的数据库引擎,可以看到读和写的性能相差不大,都能达到200万的TPS。
coolhash提供了高效的查询检索功能,可以支持key和value的同时模糊查询,下面按照600万—3亿不同的数据总量进行模糊查询,数据格式为key=n(0<n<3亿),value=n(0<n<3亿),模糊查询value包括“8888888”的数据:
CoolHashResult hr = chc.find("*", ValueFilter.contains(“8888888”))