说一下两种方法的区别:
第一种方法是效率高,当表有上亿条记录的时候,如果你使用第二种方法执行AVG(DATALENGTH(C0))是很慢的,因为SQLSERVER要统计字段大小信息。
可能十几分钟都出不来结果。
当然,第一种方法也有一些缺陷,就是当表的记录数少的时候,统计出来的每行记录占用空间是不准确的。
因为datainfo这个值是以数据页大小为单位的,因为就算表只有一条记录,那么也会占用一个数据页8KB)
那么当8KB/1 =8KB,一条记录肯定不会是8KB大小的,所以记录少的时候会不准确。
但是当记录数很多的时候,就准确了。

看一下TB106这个表统计出来的结果值

- SELECT AVG(DATALENGTH(C0))+AVG(DATALENGTH(C1))+AVG(DATALENGTH(C2))+AVG(DATALENGTH(C3)) FROM [dbo].[TB106]
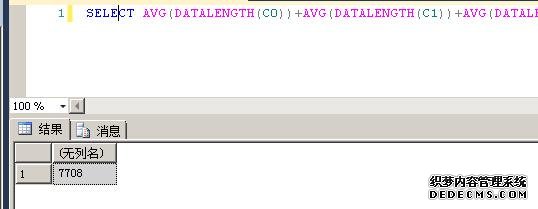
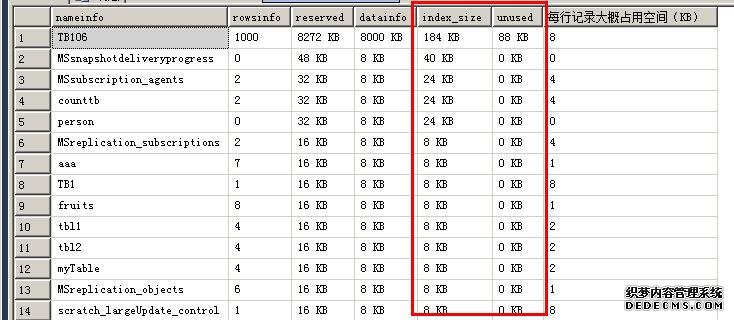
可以看到是比较准确的
注意:
无论方法一还是方法二都不包括索引所占用的空间 !!
总结
大家平时一定会想:究竟DBA有什么作用?
在这里就给大家一个例子了,在工作中,程序员是不会关心他要查询的数据的大小的,他不管三七二十一只要把数据select出来就行了,然后收工。
DBA这里就要解决数据查询不出来的问题,一般的程序员觉得查询500条数据是很少的,根本不会关心表设计,表的字段的数据类型。
当工作越来越多,开发任务越来越重的时候更是这样。
所以本人觉得DBA这个角色还是比较重要的o(∩_∩)o
如有不对的地方,欢迎大家拍砖o(∩_∩)o
2014-7-7 脚本bug修复
由于算出来每行记录的精度有问题,我又对脚本的精度进行了改进
- CREATE TABLE #tablespaceinfo
- (
- nameinfo VARCHAR(50) ,
- rowsinfo BIGINT ,
- reserved VARCHAR(20) ,
- datainfo VARCHAR(20) ,
- index_size VARCHAR(20) ,
- unused VARCHAR(20)
- )
- DECLARE @tablename VARCHAR(255);
- DECLARE Info_cursor CURSOR
- FOR
- SELECT '[' + [name] + ']'
- FROM sys.tables
- WHERE type = 'U';
- OPEN Info_cursor
- FETCH NEXT FROM Info_cursor INTO @tablename
- WHILE @@FETCH_STATUS = 0
- BEGIN
- INSERT INTO #tablespaceinfo
- EXEC sp_spaceused @tablename
- FETCH NEXT FROM Info_cursor
- INTO @tablename
- END
- CLOSE Info_cursor
- DEALLOCATE Info_cursor
- --创建临时表
- CREATE TABLE [#tmptb]
- (
- TableName VARCHAR(50) ,
- DataInfo BIGINT ,
- RowsInfo BIGINT ,
- Spaceperrow AS ( CASE RowsInfo
- WHEN 0 THEN 0
- ELSE CAST(DataInfo AS decimal(18,2))/CAST(RowsInfo AS decimal(18,2))
- END ) PERSISTED
- )
- --插入数据到临时表
- INSERT INTO [#tmptb]
- ( [TableName] ,
- [DataInfo] ,
- [RowsInfo]
- )
- SELECT [nameinfo] ,
- CAST(REPLACE([datainfo], 'KB', '') AS BIGINT) AS 'datainfo' ,
- [rowsinfo]
- FROM #tablespaceinfo
- ORDER BY CAST(REPLACE(reserved, 'KB', '') AS INT) DESC
- --汇总记录
- SELECT [tbspinfo].* ,
- [tmptb].[Spaceperrow] AS '每行记录大概占用空间KB)'
- FROM [#tablespaceinfo] AS tbspinfo ,
- [#tmptb] AS tmptb
- WHERE [tbspinfo].[nameinfo] = [tmptb].[TableName]
- ORDER BY CAST(REPLACE([tbspinfo].[reserved], 'KB', '') AS INT) DESC
- DROP TABLE [#tablespaceinfo]
- DROP TABLE [#tmptb]

本文出自:http://www.cnblogs.com/lyhabc/p/3828496.html
本站文章为和通数据库网友分享或者投稿,欢迎任何形式的转载,但请务必注明出处.
同时文章内容如有侵犯了您的权益,请联系QQ:970679559,我们会在尽快处理。