Oracle性能调整与优化(二)(1)
51CTO快译】为了能取得圆满成功,我将涉及到一些预备步骤,它们将在查看发生了什么时需要,这些步骤包括运行plustrce SQL脚本、创建一个“EXPLAIN_PLAN”表、授予角色、配置sql*plus环境查看执行计划。所有这些步骤都包括在“Oracle 9i R2数据库性能调整指南和参考”中“在sql*plus中使用自动跟踪”,对于Oracle 10g,这些步骤包括在“sql*plus用户指南和参考10.2版”中“调整sql*plus”。
预备步骤
如果角色PLUSTRACE不存在,用ORACLE_HOME\sqlplus\admin目录下的PLUSTRCE SQL脚本来创建它,这个脚本相当简单:
drop role plustrace; create role plustrace; grant select on v_$sesstat to plustrace; grant select on v_$statname to plustrace; grant select on v_$mystat to plustrace; grant plustrace to dba with admin option; |
检查角色使用情况:
SQL> select role from dba_roles where role = 'PLUSTRACE'; ROLE ---------------- PLUSTRACE |
用户必须有或有权限访问)一个PLAN_TABLE它可以被命名为其他名字,但是默认的名字非常好),这个表是用ORACLE_HOME\rdbms\admin目录下的UTLXPLAN SQL脚本创建的。
SQL> show user USER is "SYSTEM" SQL> @?\rdbms\admin\utlxplan Table created. SQL> create public synonym plan_table for system.plan_table; Synonym created. SQL> grant select, update, insert, delete on plan_table to <你的用户名>; Grant succeeded. SQL> grant plustrace to <你的用户名>; Grant succeeded. |
我们的例子中使用的用户是HR可以在Oracle提供的样本方案中找到)。
SQL> conn hr/hr Connected. SQL> set autotrace on SQL> select * from dual; D - X |
因为autotrace被设置为on,你将能够看到执行计划和一些统计信息,你看到的输出应该与下面的内容类似:
Execution Plan ---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=ALL_ROWS (Cost=2 Card=1 Bytes=2) 1 0 TABLE ACCESS (FULL) OF 'DUAL' (TABLE) (Cost=2 Card=1 Bytes=2) Statistics ---------------------------------------------------------- 24 recursive calls 0 db block gets 6 consistent gets 1 physical reads 0 redo size 389 bytes sent via SQL*Net to client 508 bytes received via SQL*Net from client 2 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 1 rows processed |
要取消查询结果,在set语句中使用“traceonly”。
使用绑定变量
在任何DBA帮助类型的网站上,常常会看到一点使用绑定变量的建议,但是步骤或包括在这些步骤中的指令很少,这里有一个创建和使用绑定变量的简单方法。
SQL> variable department_id number SQL> begin 2 :department_id := 80; 3 end; 4 / PL/SQL procedure successfully completed. SQL> print department_id DEPARTMENT_ID ------------- 80 |
现在我们对使用和不使用绑定变量查询雇员id两种情况做一下比较使用traceonly关闭输出)。
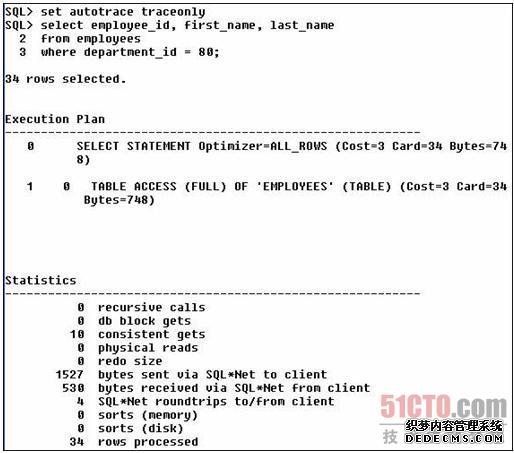
现在让我们使用绑定变量:
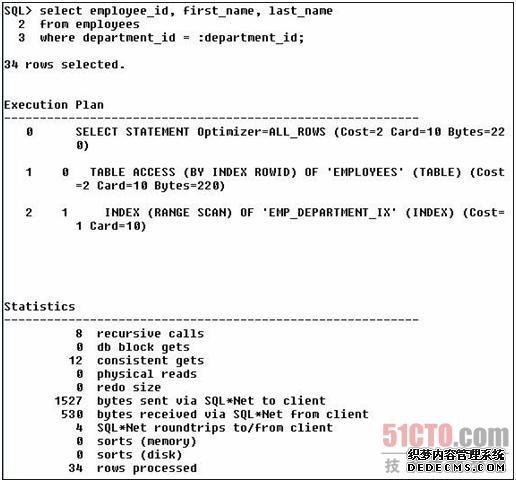
ok!区别不是太大cost从3变为2),但这是一个小例子表只有107行),当工作在一个更大的表上会有更多区别吗?使用SH方案,它的SALES表有超过900,000行数据。
SQL> select prod_id, count(prod_id) 2 from sales 3 where prod_id > 130 4 group by prod_id; |

同样的查询,但这次使用一个绑定变量:
SQL> variable prod_id number SQL> begin 2 :prod_id := 130; 3 end; 4 / PL/SQL procedure successfully completed. SQL> print prod_id PROD_ID ---------- 130 SQL> select prod_id, count(prod_id) 2 from sales 3 where prod_id > :prod_id 4 group by prod_id; |

cost从540变为33了,这一下就显得十分明显了,其中最主要的受益是使用绑定变量的查询,你要做的就是为这个变量替换一个新值。