详解通过结合文件系统给数据库瘦身
通过文件系统给数据库瘦身,就是将数据库中的大数据,不参与搜索的数据通过文件流的方式序列化到硬盘的某个位置,存储位置使用hash路径,即通过数据库表主键生成hashcode 然后两两切分实现一个hash路径,保证一个目录下面的子文件和文件个数最多198个,保证了系统的检索速度.
这里的大数据举一个例子就是,比如公司表中,一般都有公司简介,但是公司简介这个列的内容量比这个整条数据的体积都大,而公司简介根本不参与搜索,列表等操作,我们就可以讲这个数据提出来,放到文件系统中,等需要的时候我们再把它读取出来,如果修改了就重新保存.
程序实现的目标和目的就是这样了.
由于公司使用Ibatis作为数据库层的处理框架,接下来的任务就是修改Ibatis源代码实现上述目标.
至于如何修改Ibatis,我会后续写文章来介绍. 这里我们先讨论下这个方案的可行性
为了一个更直接的印象,先看看具体的效果

数据库的字段

这里可以看到 数据字段只有四个,比对象少了两个字段
那两个字段就会被存储到文件系统中

执行了插入操作,以下是日志文件

对应的文件系统中的文件

用二进制的方式打开这个文件可以看到

读取单条数据
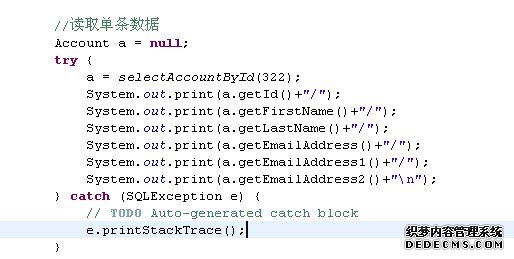
读取结果

虽然程序使用java写的,但是Ibatis也有.net版本基本应该差不多,而我更加喜欢博客园的活跃,就发到这里了 ,大家讨论下 这样做到底有没有好处
- Oracle数据库开发经验浅谈
- 横向比较数据库中不同的索引机制
- 关系数据库的末日是否已经来临
本站文章为和通数据库网友分享或者投稿,欢迎任何形式的转载,但请务必注明出处.
同时文章内容如有侵犯了您的权益,请联系QQ:970679559,我们会在尽快处理。