Hive架构及Hive On Spark,
Hive的所有数据都存在HDFS中.
(1)Table:每个表都对应在HDFS中的目录下,数据是经过序列化后存储在该目录中。同时Hive也支持表中的数据存储在其他类型的文件系统中,如NFS或本地文件系统。
(2)Partition(分区):Hive中的分区类似于RDBMS中的索引,每个Partition都有一个对应的目录,查询的时候可以减少数据的规模。
(3)Bucket(桶):即使将数据分区后,每个分区的规模可能依旧会很大,可以根据关键字的Hash结果将数据分成多个Bucket,每个Bucket对应一个文件。
HvieQL支持类似于SQL的查询语言,大体可分为以下几种类型.
DDL:类似于创建数据库(create database),创建表(create table),删除表(drop table)等.
DML:对于数据的查询(select)或添加(insert into overwrite)。
UDF:自定义查询函数。
Hive的整体架构图如下:
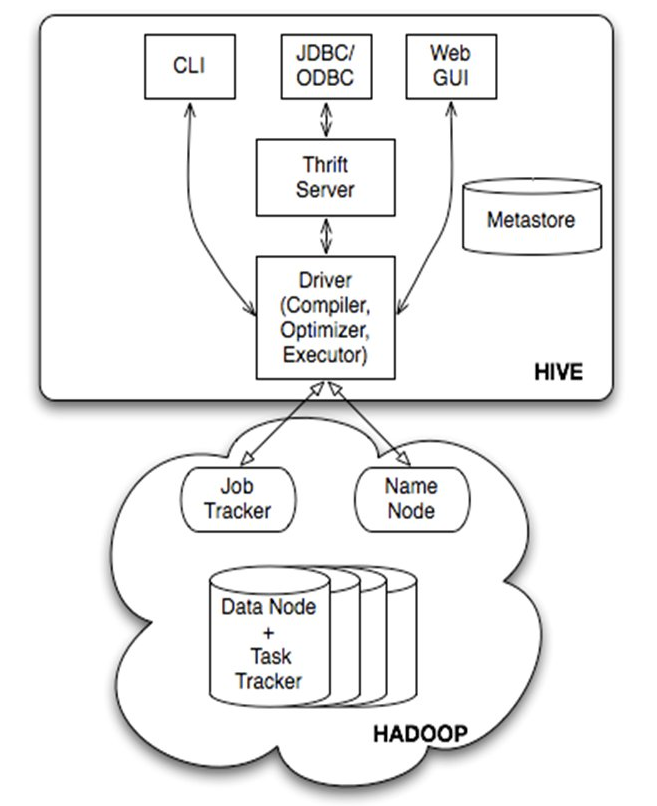
Hive拥有自己的语法树解析(Parser)、语义分析(Semantic Analyser)、以及查询优化器(Optimizer),最终以MapReduce的形式生成Job,交给Hadoop进行执行。项目开发中,由于Spark的Catalyst解析还太过简陋,一般声明对象时,还是用HiveContext.下面举个简单的例子:
import hiveContext._
val sqlContext = new org.apache.spark.sql.hive.HiveContext(sc)
sqlContext("create table yangsy (key int, value String)"
//将本地目录下的文件加载到HDFS的HIVE表中
sqlContext("load data local inpath '/home/coc/XXX.csv' into table yangsy")
//查询
sqlContext("From yangsy select key,value").collect().foreach(println)
sqlContext("drop table yangsy")
其实collect()函数已经过时。。。。但是为了触发action操作,就必须用,cache()函数只将运算后的数据存入内存,然而并没有什么卵用,因为它是transformation操作。
Spark对HiveQL所做的优化主要体现在Query相关的操作,其他的依旧使用Hive的原生执行引擎。在logicalPlan到physicalPlan的转换过程中,toRDD是最关键的。 源码如下:
override lazy val toRdd:RDD[Row] =
analyzed match{
case NativeCommand(cmd) =>
val output = runSqlHive(cmd)
if(output.size == 0){
emptyResult
}else{
val asRows = output.map(r => new GenericRow(r.split("\t".asInstanceOf[Array[Any]]))
sparkContext.parallelize(asRows,1)
}
case _ =>
executedPlan.execute().map(_.copy())
}
在Hive解析过程中增加了两个规则,分别是HiveTypeCoercion和PreInsertionCasts,其中要注意Catalog的用途,它是HiveMetastoreCatalog的实例。
HiveMetastoreCatalog是Spark中对Hive Metastore访问的wrapper.HiveMetastoreCatalog通过调用相应的Hive API可以获得数据库中的表及表的分区,也可创建表。它会通过Hive client来访问MetaStore的元数据。流程如下所示:
Hive: hiveql -> queryExecutor ->HiveMetastoreCatalog ->MetaStore
SparkSQL: hiveql -> queryExecutor (toRDD)-> Spark RDDS -> HiveMetastoreCatalog ->MetaStore