Hbase 学习(五) 调优,
1.垃圾回收器调优
当我们往hbase写入数据,它首先写入memstore当中,当menstore的值大于hbase.hregion.memstore.flush.size参数中设置的值后,就会写入硬盘。 在hbase-env.sh文件中,我们可以设置HBASE_OPTS或者HBASE_REGIONSERVER_OPTS,后者只影响region server进程。export HBASE_REGIONSERVER_OPTS="-Xmx8g -Xms8g -Xmn128m -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:$HBASE_HOME/logs/gc-$(hostname)-hbase.log"2.MemStore-Local Allocation Buffer
MemStore-Local Allocation Buffer,是Cloudera在HBase 0.90.1时提交的一个patch里包含的特性。它基于Arena Allocation解决了HBase因Region flush导致的内存碎片问题。 MSLAB的实现原理(对照Arena Allocation,HBase实现细节):-
MemstoreLAB为Memstore提供Allocator。
-
创建一个2M(默认)的Chunk数组和一个chunk偏移量,默认值为0。
-
当Memstore有新的KeyValue被插入时,通过KeyValue.getBuffer()取得data bytes数组。将data复制到Chunk数组起始位置为chunk偏移量处,并增加偏移量=偏移量+data.length。
-
当一个chunk满了以后,再创建一个chunk。
-
所有操作lock free,基于CMS原语。
-
KeyValue原始数据在minor gc时被销毁。
-
数据存放在2m大小的chunk中,chunk归属于memstore。
-
flush时,只需要释放多个2m的chunks,chunk未满也强制释放,从而为Heap腾出了多个2M大小的内存区间,减少碎片密集程度。
3.压缩存储
直接上图吧,说多了没用。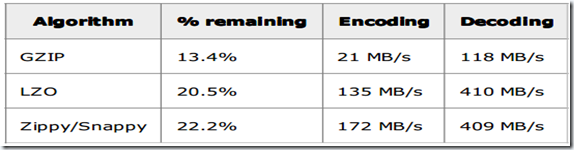
推荐使用Snappy,性能最好,但是Snappy要单独安装,安装教程等我装成功了,再发一个文档出来吧。
4.优化Splits and Compactions
对于实时性要求稳定的系统来说,不定时的split和compact会使集群的响应时间出现比较大的波动,因此建议把split和compact关闭,手动进行操作,比如我们把hbase.hregion.max.filesize设置成100G(major compaction大概需要一小时,设置太大了,compaction会需要更多的时间),major compaction是必须要做的,群里有个网友给数据设置了过期时间,数据被逻辑删除了,但是没有释放硬盘空间,why?没有进行major compaction,最后是手动进行的合并。5.平衡分布
在我们设计rowkey的时候,在前面加上随机数,比如0rowkey-1,1rowkey-2,0rowkey-3,1rowkey-4,去前面加上个随机数,就会有负载均衡的效果,但是如果这样做了,某个机器的数据还是比别的机器要多很多,这个怎么办呢?我们可以手动调用move()方法,通过shell或者HBaseAdmin类,或者调用unassign()方法,数据就会转移了。
本站文章为和通数据库网友分享或者投稿,欢迎任何形式的转载,但请务必注明出处.
同时文章内容如有侵犯了您的权益,请联系QQ:970679559,我们会在尽快处理。