MySQL必知必会1-20章读书笔记,
MySQL备忘
目录
目录
- 使用MySQL
- 检索数据
- 排序检索数据
- 过滤数据
- 数据过滤
- 用通配符进行过滤
- 用正则表达式进行搜索
- 创建计算字段
- 使用数据处理函数
- 数值处理函数
- 汇总数据
- 分组数据
- 使用子查询
- 作为计算字段使用子查询
- 联结表
- 创建高级联结
- 组合查询
- 全文本搜索
- 插入数据
- 更新和删除数据
使用MySQL
-
mysql -u<usr> -p -h<host> -P <port>分别指明用户名,主机名,端口号 -
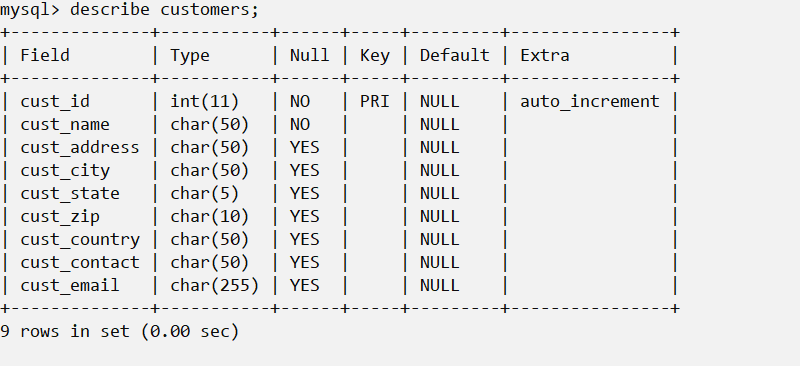
show columns from <table>对每个字段返回一行,其中的信息分别是字段名,数据类型,是否允许为空,键信息,默认值及其他信息describe <table>与上同
show status显示广泛的服务器状态信息SHOW CREATE DATABASE <database>和SHOW CREATE TABLE <table>,分别用来显示创建特定数据库或表的MySQL语句SHOW GRANTS,用来显示授予用户(所有用户或特定用户)的安全权限SHOW ERRORS和SHOW WARNINGS用来显示服务器错误或警告消息
检索数据
通过select * from somewhere选择所有的列时,列的顺序一般情况下是列在表定义中出现的顺序,但有时也不是,表的模式的变化(如添加或删除列)可能会导致顺序的变化。
一般情况不要使用通配符,除了的确需要,使用通配符会降低检索和应用程序的性能
select distinct <variable> from <table>来指示MySQL只返回不同的值
注意:
不能部分使用DISTINCT DISTINCT关键字应用于所有列而不仅是前置它的列。如果给出SELECT DISTINCT vend_id, prod_price,除非指定的两个列都相同,否则所有行都将被检索出来。也就是说select distinct a, b, c from table相当于select a, b, c from table group by a, b, c会选出所有a, b, c的不同组合。
select <variable> from <table> limit <n>使用LIMIT子句来返回结果的第一行或前几行
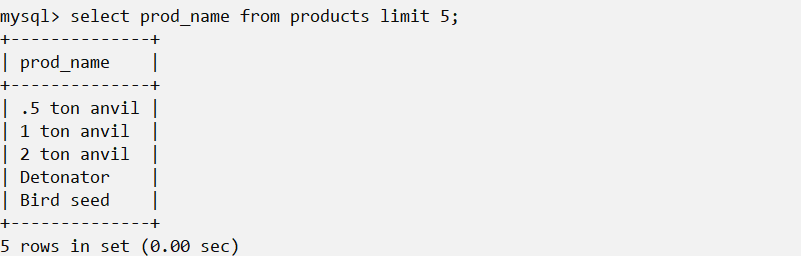
限制返回结果不多于5行,此外,还可以指定哟检索的开始行和行数。
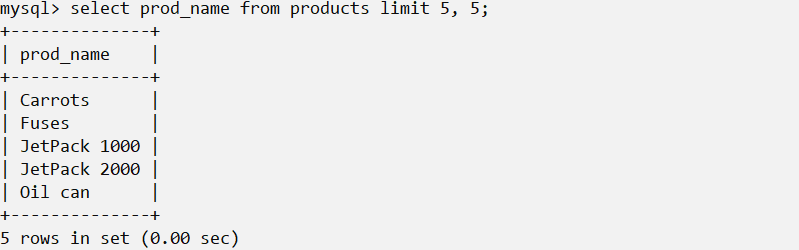
行0 检索出来的第一行为行0而不是行1。因此,LIMIT 1, 1将检索出第二行而不是第一行。
在行数不够时 LIMIT中指定要检索的行数为检索的最大行数。如果没有足够的行(例如,给出LIMIT 10, 5,但只有13行),MySQL将只返回它能返回的那么多行。
MySQL 5的LIMIT语法 LIMIT 3, 4的含义是从行4开始的3行还是从行3开始的4行?如前所述,它的意思是从行3开始的4行,这容易把人搞糊涂。由于这个原因,MySQL 5支持LIMIT的另一种替代语法。LIMIT 4 OFFSET 3意为从行3开始取4行,就像LIMIT 3, 4一样
排序检索数据
检索出的数据并不是以纯粹的随机顺序显示的。如果不排序,数据一般将以它在底层表中出现的顺序显示。这可以是数据最初添加到表中的顺序。但是,如果数据后来进行过更新或删除,则此顺序将会受到MySQL重用回收存储空间的影响。因此,如果不明确控制的话,不能(也不应该)依赖该排序顺序。关系数据库设计理论认为,如果不明确规定排序顺序,则不应该假定检索出的数据的顺序有意义。
子句(clause) SQL语句由子句构成,有些子句是必需的,而有的是可选的。一个子句通常由一个关键字和所提供的数据组成。子句的例子有SELECT语句的FROM子句
select <variables> from <table> order by <variable> [desc]为了明确地排序用select语句检索出的数据,可以使用order by子句。 order by 子句取一个或者多个列的名字,据此对数据的数据进行排序。
通过非选择列进行排序 通常,ORDER BY子句中使用的列将是为显示所选择的列。但是,实际上并不一定要这样,用非检索的列排序数据是完全合法的。
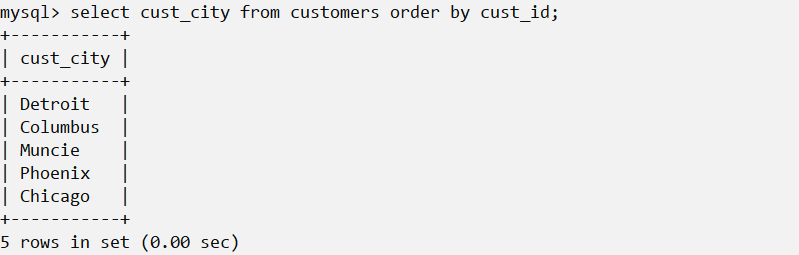
按列降序排列:
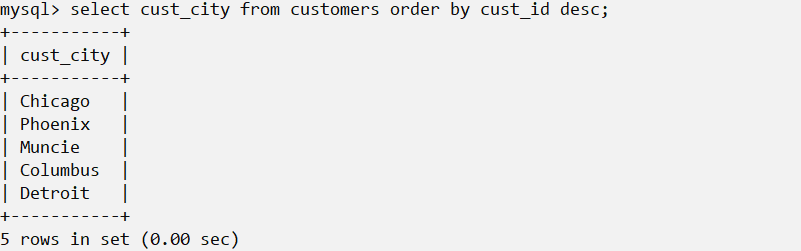
DESC关键字只应用到直接位于其前面的列名。
在多个列上降序排序 如果想在多个列上进行降序排序,必须对每个列指定DESC关键字。
区分大小写和排序顺序 在对文本性的数据进行排序时,A与a相同吗?a位于B之前还是位于Z之后?这些问题不是理论问题,其答案取决于数据库如何设置。在字典(dictionary)排序顺序中,A被视为与a相同,这是MySQL(和大多数数据库管理系统)的默认行为。但是,许多数据库管理员能够在需要时改变这种行为(如果你的数据库包含大量外语字符,可能必须这样做)。这里,关键的问题是,如果确实需要改变这种排序顺序,用简单的ORDER BY子句做不到。你必须请求数据库管理员的帮助。
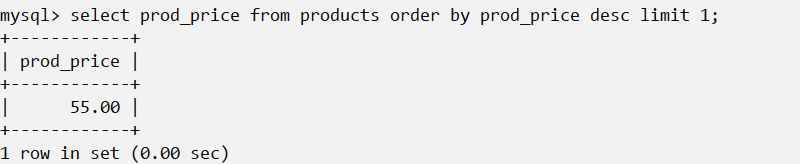
这里通过order by 和limit的组合使用来得到价格最高的商品。
ORDER BY子句的位置 在给出ORDER BY子句时,应该保证它位于FROM子句之后。如果使用LIMIT,它必须位于ORDER BY之后。使用子句的次序不对将产生错误消息。请注意,order by子句必须是select语句中的最后一个子句。否则将产生错误信息。
过滤数据
在SELECT语句中,数据根据WHERE子句中指定的搜索条件进行过滤。WHERE子句在表名(FROM子句)之后给出
SQL过滤与应用过滤 数据也可以在应用层过滤。为此目的,SQL的SELECT语句为客户机应用检索出超过实际所需的数据,然后客户机代码对返回数据进行循环,以提取出需要的行。通常,这种实现并不令人满意。因此,对数据库进行了优化,以便快速有效地对数据进行过滤。让客户机应用(或开发语言)处理数据库的工作将会极大地影响应用的性能,并且使所创建的应用完全不具备可伸缩性。此外,如果在客户机上过滤数据,服务器不得不通过网络发送多余的数据,这将导致网络带宽的浪费。
| 操作符 | 说明 |
|---|---|
| = | 等于 |
| <> | 不等于 |
| != | 不等于 |
| < | 小于 |
| <= | 小于等于 |
| > | 大于 |
| >= | 大于等于 |
| BETWEEN | 在指定的两个值之间 |
接着看一个特例:
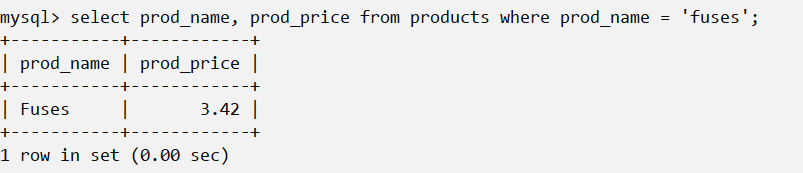
检查WHERE prod_name=‘fuses’语句,它返回prod_name的值为Fuses的一行。MySQL在执行匹配时默认不区分大小写,所以fuses与Fuses匹配。
何时使用引号 如果仔细观察上述WHERE子句中使用的条件,会看到有的值括在单引号内(如前面使用的'fuses'),而有的值未括起来。单引号用来限定字符串。如果将值与串类型的列进行比较,则需要限定引号。用来与数值列进行比较的值不用引号。
为了检查某个范围的值,可使用BETWEEN操作符。其语法与其他WHERE子句的操作符稍有不同,因为它需要两个值,即范围的开始值和结束值。例如,BETWEEN操作符可用来检索价格在5美元和10美元之间或日期在指
定的开始日期和结束日期之间的所有产品。
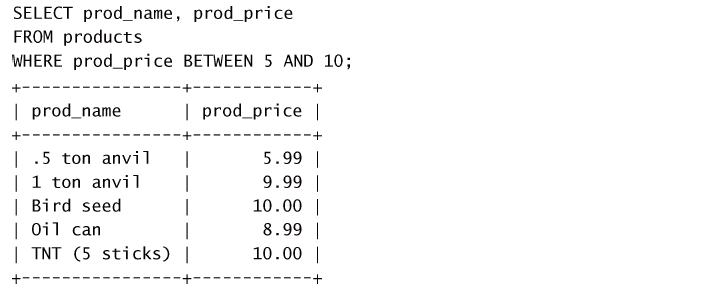
从这个例子中可以看到,在使用BETWEEN时,必须指定两个值——所需范围的低端值和高端值。这两个值必须用AND关键字分隔。BETWEEN匹配范围中所有的值,包括指定的开始值和结束值。
在创建表时,表设计人员可以指定其中的列是否可以不包含值。在一个列不包含值时,称其为包含空值NULL。
NULL 无值(no value),它与字段包含0、空字符串或仅仅包含空格不同。
通过IS NULL子句过滤含空值的行:

NULL与不匹配 在通过过滤选择出不具有特定值的行时,你可能希望返回具有NULL值的行。但是,不行。因为未知具有特殊的含义,数据库不知道它们是否匹配,所以在匹配过滤或不匹配过滤时不返回它们。因此,在过滤数据时,一定要验证返回数据中确实给出了被过滤列具有NULL的行。
也就是说,当我们需要某一行时,尤其是哪一行某个属性为空值,需要特别注意。
数据过滤
MySQL中的逻辑操作符有AND,OR, NOT。可以通过组合使用与或非和WHERE子句来获得更复杂的条件。与绝大多数语言一样,有优先级
| 优先级顺序 | 运算符 |
|---|---|
| 1 | !(按位非) |
| 2 | -(负号),~(按位反) |
| 3 | ^(按位异或) |
| 4 | *, /, %, DIV, MOD |
| 5 | -, + |
| 6 | <<, >>(移位运算符) |
| 7 | &(按位与) |
| 8 | |(按位或) |
| 9 | =, <=>, >=, >, <=, <, <>, !=, IS, LIKE, REGEXP, IN |
| 10 | BETWEEN,CASE, WHEN, THEN, ELSE |
| 11 | NOT |
| 12 | &&, AND |
| 13 | ||, OR, XOR |
| 14 | := |
参考:[菜鸟教程](https://www.runoob.com/mysql/mysql-operator.html)
备注:<=>用以比较和
NULL是否相等,比如NULL <=> NULL返回1,而只当一个操作码为NULL的时候,返回0。注意,不用<=>时,NULL表现出传染性。
同样的,类似于绝大多数语言,在条件表达式含糊不清时,使用( )来显示的指明运算优先次序。
select <variables> from <table> where <variable> in <tuple> order by <variable>通过使用in (...)操作符来指定条件范围。
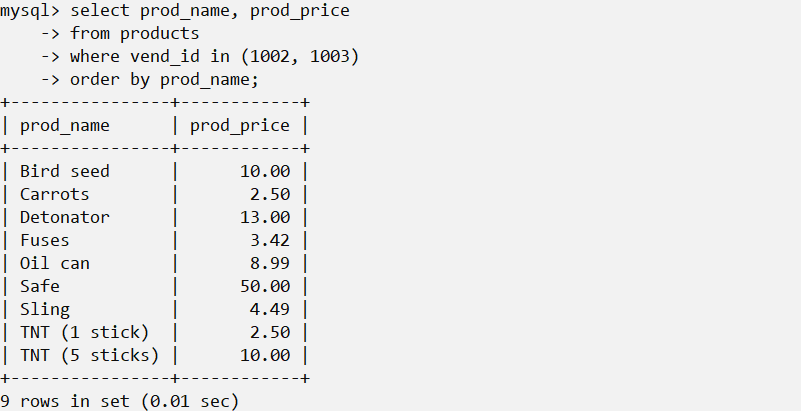
为什么要使用IN操作符呢?
WHERE子句中的NOT操作符有且只有一个功能,那就是否定它之后所跟的任何条件。
MySQL中的NOT MySQL支持使用NOT 对IN 、BETWEEN 和EXISTS子句取反,这与多数其他DBMS允许使用NOT对各种条件取反有很大的差别。
用通配符进行过滤
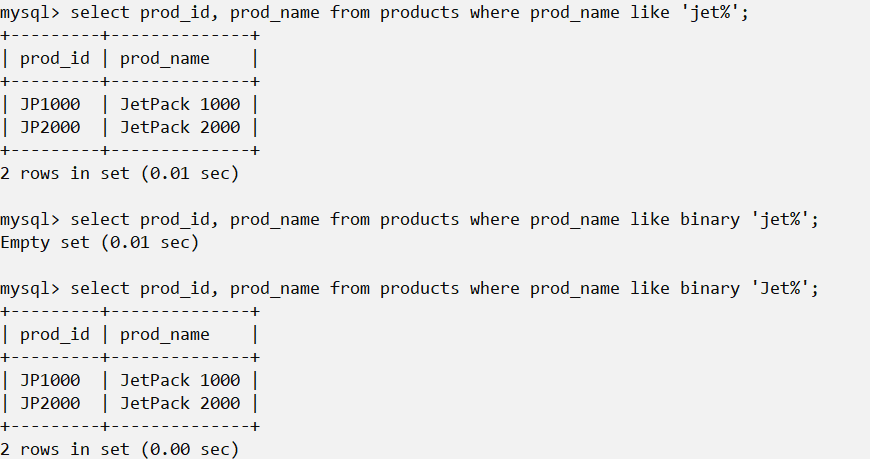
select <variables> from <table> where <variable> like <pattern>而pattern中的%通配符表示任何字符出现任意次数。
区分大小写 根据MySQL的配置方式,搜索可以是区分大小写的。如果区分大小写,'jet%'与JetPack 1000将不匹配。
这个时候可以在like后加binary来表示区分大小写。
注意:
注意尾空格 尾空格可能会干扰通配符匹配。例如,在保存词anvil 时, 如果它后面有一个或多个空格, 则子句WHERE prod_name LIKE '%anvil'将不会匹配它们,因为在最后的l后有多余的字符。解决这个问题的一个简单的办法是在搜索模式最后附加一个%。一个更好的办法是使用函数去掉首尾空格。
注意NULL 虽然似乎%通配符可以匹配任何东西,但有一个例外,即NULL。即使是WHERE prod_name LIKE '%'也不能匹配用值NULL作为产品名的行。(可以理解成NA的传染性)
select prod_id, prod_name from products where prod_name like '_ton anvil'这里出现的_通配符用途与%一致,但下划线只匹配单个字符而不是多个字符。
MySQL的通配符很有用,但是这种有用是有代价的:通配符搜索的处理一般要比前面讨论的其他搜索要花的时间更长。
一些使用通配符的技巧:
用正则表达式进行搜索
正则表达式是用来匹配文本的特殊的串(字符集合)。MySQL用WHERE子句对正则表达式提供了初步的支持,允许你指定正则表达式,过滤SELECT检索出的数据。
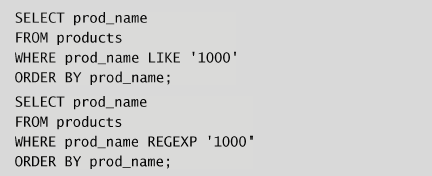
select <variables> from <table> where <variable> rlike/regexp <pattern>其中RLIKE或者REGEXP后所跟的模式即为正则表达式。
例如select prod_name from products where prod_name regexp '1000' order by prod_name筛选出所有prod_name包含1000的行。
LIKE与REGEXP 在LIKE和REGEXP之间有一个重要的差别。请
看以下两条语句:
如果执行上述两条语句,会发现第一条语句不返回数据,而第二条语句返回一行。为什么?正如第8章所述,LIKE匹配整个列。如果被匹配的文本在列值中出现,LIKE将不会找到它,相应的行也不被返回(除非使用通配符)。而REGEXP在列值内进行匹配,如果被匹配的文本在列值中出现,REGEXP将会找到它,相应的行将被返回。这是一个非常重要的差别。那么,REGEXP能不能用来匹配整个列值(从而起与LIKE相同的作用)?答案是肯定的,使用^和$定位符(anchor)即可
匹配不区分大小写 MySQL中的正则表达式匹配(自版本3.23.4后)不区分大小写(即,大写和小写都匹配)。为区分大小写,可使用BINARY关键字,如WHERE prod_name REGEXP BINARY 'JetPack .000'。
匹配\ 为了匹配反斜杠(\)字符本身,需要使用\\。
\或\? 多数正则表达式实现使用单个反斜杠转义特殊字符,以便能使用这些字符本身。但MySQL要求两个反斜杠(MySQL自己解释一个,正则表达式库解释另一个)。
匹配字符类
存在找出你自己经常使用的数字、所有字母字符或所有数字字母字符等的匹配。为更方便工作,可以使用预定义的字符集,称为字符类(character class)。

定位符
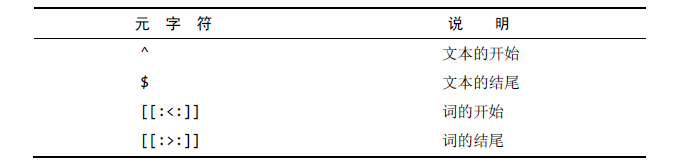
使REGEXP起类似LIKE的作用 利用定位符,通过用^开始每个表达式,用$结束每个表达式,可以使REGEXP的作用与LIKE一样。
简单的正则表达式测试 可以在不使用数据库表的情况下用SELECT来测试正则表达式。REGEXP检查总是返回0(没有匹配)或1(匹配)。可以用带文字串的REGEXP来测试表达式,并试
验它们。相应的语法如下:
select 'help' regexp '[0-9]'这个例子显然将返回0(因为文本hello中没有数字)。
创建计算字段
存储在表中的数据往往都不是应用程序所需要的。我们需要直接从数据库中检索出转换、计算或格式化过的数据;而不是检索出数据,然后再在客户机应用程序或报告程序中重新格式化。计算字段是在select语句内创建的。
客户机与服务器的格式 可在SQL语句内完成的许多转换和格式化工作都可以直接在客户机应用程序内完成。但一般来说,在数据库服务器上完成这些操作比在客户机中完成要快得多,因为DBMS是设计来快速有效地完成这种处理的。
-
select Concat(RTrim(vend_name), '(', RTrim(vend_country), ')') from vendors order by vend_name通过Concat()函数连接字符串与变量,通过Trim()函数去除字符创两端的空格。 -
select Concat(RTrim(vend_name), '(', RTrim(vend_country), ')') as vend_title from vendors order by vend_name使用AS关键字来指定别名。此外,还可以直接在
select语句中创建计算字段。如: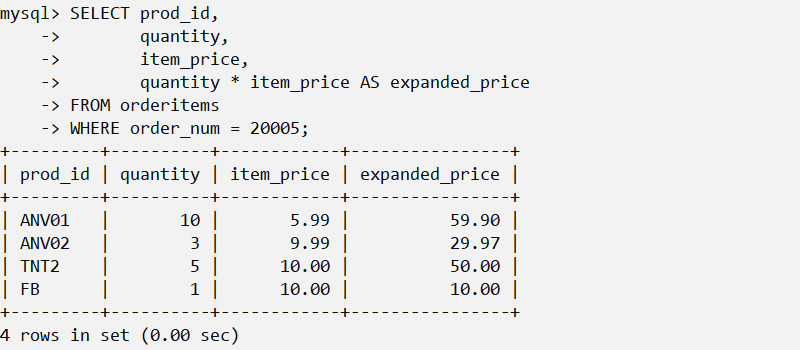
使用数据处理函数
函数没有SQL的可移植性强 能运行在多个系统上的代码称为可移植的(portable)。相对来说,多数SQL语句是可移植的,在SQL实现之间有差异时,这些差异通常不那么难处理。而函数的可移植性却不强。几乎每种主要的DBMS的实现都支持其他实现不支持的函数,而且有时差异还很大。为了代码的可移植,许多SQL程序员不赞成使用特殊实现的功能。虽然这样做很有好处,但不总是利于应用程序的性能。如果不使用这些函数,编写某些应用程序代码会很艰难。必须利
用其他方法来实现DBMS非常有效地完成的工作。如果你决定使用函数,应该保证做好代码注释,以便以后你(或其他人)能确切地知道所编写SQL代码的含义。
大多数SQL实现支持以下类型的函数:
- 用于处理文本串(如删除或填充值,转换值为大写或小写)的文本函数。
- 用于在数值数据上进行算术操作(如返回绝对值,进行代数运算)的数值函数。
- 用于处理日期和时间值并从这些值中提取特定成分(例如,返回两个日期之差,检查日期有效性等)的日期和时间函数。
- 返回DBMS正使用的特殊信息(如返回用户登录信息,检查版本细节)的系统函数。
一些常用的文本处理函数:
| 函数 | 说明 |
|---|---|
| Left() | 返回串左边的字符 |
| Length() | 返回串的长度 |
| Locate() | 找出串的一个子串 |
| Lower() | 将串转化为小写 |
| LTrim() | 去掉串左边的空格 |
| Right() | 返回串右边的字符 |
| RTrim() | 去穿串右边的空格 |
| Soundex() | 返回串的SOUNDEX值[1] |
| SubString() | 返回子串的字符 |
| Upper() | 将串转化为大写 |
| Reverse() | 翻转字符串 |
[1] SOUNDEX是一个将任何文本串转换为描述其语音表示的字母数字模式的算法。SOUNDEX考虑了类似的发音字符和音节,使得能对串进行发音比较而不是字母比较。虽然SOUNDEX不是SQL概念,但MySQL(就像多数DBMS一样)都提供对SOUNDEX的支持
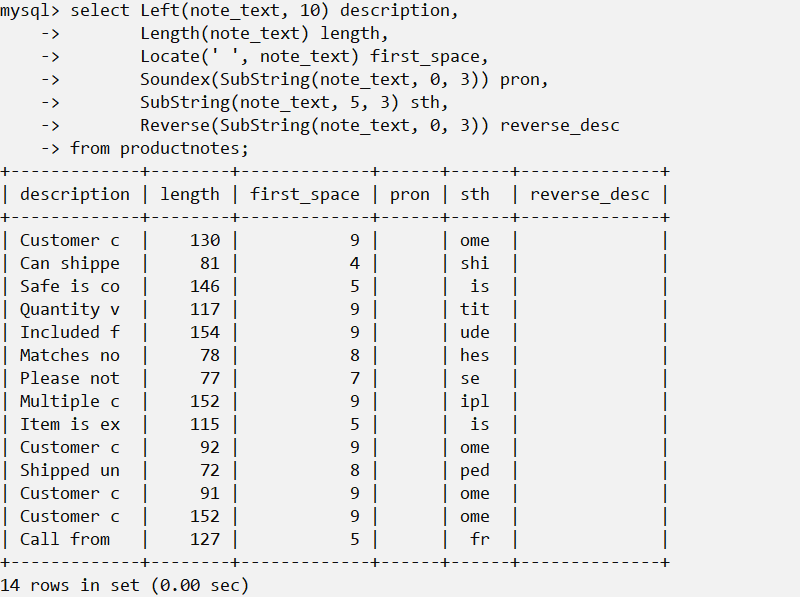
一个使用Soundex()的例子:

日期和时间常用的处理函数:
| 函数名称 | 函数功能说明 |
|---|---|
ADDDATE() |
添加日期 |
ADDTIME() |
添加时间 |
CONVERT_TZ() |
转换不同时区 |
CURDATE() |
返回当前日期 |
CURRENT_DATE() 与 CURRENT_DATE |
等同于 CURDATE() |
CURRENT_TIME() 与 CURRENT_TIME |
等同于 CURTIME() |
CURRENT_TIMESTAMP() 与 CURRENT_TIMESTAMP |
等同于 NOW() |
CURTIME() |
返回当前时间 |
DATE_ADD() |
添加两个日期 |
DATE_FORMAT() |
按指定方式格式化日期 |
DATE_SUB() |
求解两个日期的间隔 |
DATE() |
提取日期或日期时间表达式中的日期部分 |
DATEDIFF() |
求解两个日期的间隔 |
DAY() |
等同于 DAYOFMONTH() |
DAYNAME() |
返回星期中某天的名称 |
DAYOFMONTH() |
返回一月中某天的序号(1-31) |
DAYOFWEEK() |
返回参数所定影的一周中某天的索引值 |
DAYOFYEAR() |
返回一年中某天的序号(1-366) |
EXTRACT |
提取日期中的相应部分 |
FROM_DAYS() |
将一个天数序号转变为日期值 |
FROM_UNIXTIME() |
将日期格式化为 UNIX 的时间戳 |
HOUR() |
提取时间 |
LAST_DAY |
根据参数,返回月中最后一天 |
LOCALTIME() 和 LOCALTIME |
等同于 NOW() |
LOCALTIMESTAMP 和 LOCALTIMESTAMP() |
等同于 NOW() |
MAKEDATE() |
基于给定参数年份和所在年中的天数序号,返回一个日期 |
MAKETIME |
MAKETIME() |
MICROSECOND() |
返回参数所对应的毫秒数 |
MINUTE() |
返回参数对应的分钟数 |
MONTH() |
返回传入日期所对应的月序数 |
MONTHNAME() |
返回月的名称 |
NOW() |
返回当前日期与时间 |
PERIOD_ADD() |
为年-月组合日期添加一个时段 |
PERIOD_DIFF() |
返回两个时段之间的月份差值 |
QUARTER() |
返回日期参数所对应的季度序号 |
SEC_TO_TIME() |
将描述转变成 'HH:MM:SS' 的格式 |
SECOND() |
返回秒序号(0-59) |
STR_TO_DATE() |
将字符串转变为日期 |
SUBDATE() |
三个参数的版本相当于 DATE_SUB() |
SUBTIME() |
计算时间差值 |
SYSDATE() |
返回函数执行时的时间 |
TIME_FORMAT() |
提取参数中的时间部分 |
TIME_TO_SEC() |
将参数转化为秒数 |
TIME() |
提取传入表达式的时间部分 |
TIMEDIFF() |
计算时间差值 |
TIMESTAMP() |
单个参数时,函数返回日期或日期时间表达式;有2个参数时,将参数加和 |
TIMESTAMPADD() |
为日期时间表达式添加一个间隔 INTERVAL |
TIMESTAMPDIFF() |
从日期时间表达式中减去一个间隔 INTERVAL |
TO_DAYS() |
返回转换成天数的日期参数 |
UNIX_TIMESTAMP() |
返回一个 UNIX 时间戳 |
UTC_DATE() |
返回当前的 UTC 日期 |
UTC_TIME() |
返回当前的 UTC 时间 |
UTC_TIMESTAMP() |
返回当前的 UTC 时间与日期 |
WEEK() |
返回周序号 |
WEEKDAY() |
返回某天在星期中的索引值 |
WEEKOFYEAR() |
返回日期所对应的星期在一年当中的序号(1-53) |
YEAR() |
返回年份 |
YEARWEEK() |
返回年份及星期序号 |
具体用法参照:极客学院
应该总是使用4位数字的年份 支持2位数字的年份,MySQL处理00-69为2000-2069,处理70-99为1970-1999。虽然它们可能是打算要的年份,但使用完整的4位数字年份更可靠,因为
MySQL不必做出任何假定。
数值处理函数
| 函数名称 | 函数说明 |
|---|---|
ABS() |
返回数值表达式的绝对值 |
ACOS() |
返回数值表达式的反余弦值。如果参数未在[-1, 1]区间内,则返回 NULL |
ASIN() |
返回数值表达式的反正弦值。如果参数未在[-1, 1]区间内,则返回 NULL |
ATAN() |
返回数值表达式的反正切值 |
ATAN2() |
返回两个参数的反正切值 |
BIT_AND() |
返回表达式参数中的所有二进制位的按位与运算结果 |
BIT_COUNT() |
返回传入的二进制值的字符串形式 |
BIT_OR() |
返回表达式参数中的所有二进制位的按位或运算结果 |
CEIL() |
返回值为不小于传入数值表达式的最小整数值 |
CEILING() |
同CEIL()返回值为不小于传入数值表达式的最小整数值 |
CONV() |
转换数值表达式的进制 |
COS() |
返回所传入数值表达式(以弧度计)的余弦值 |
COT() |
返回所传入数值表达式的余切值 |
DEGREES() |
将数值表达式参数从弧度值转变为角度值 |
EXP() |
返回以e(自然对数的底数)为底,以所传入的数值表达式为指数的幂 |
FLOOR() |
返回不大于所传入数值表达式的最大整数 |
FORMAT() |
将数值表达式参数四舍五入到一定的小数位 |
GREATEST() |
返回传入参数的最大值 |
INTERVAL() |
比较所传入的多个表达式:expr1、expr2、expr3……,如果 expr1 < expr2,则返回0;如果 expr1 < expr3,则返回1……以此类推 |
LEAST() |
返回传入参数中的最小值 |
LOG() |
返回传入数值表达式的自然对数 |
LOG10() |
返回传入数值表达式的常用对数(以10为底的对数) |
MOD() |
返回参数相除的余数 |
OCT() |
返回传入数值表达式的八进制数值的字符串表现形式。如果传入值为 NULL,则返回 NULL |
PI() |
返回 π 值 |
POW() |
返回两个参数的幂运算结果,其中一个参数为底,另一个参数为它的指数。 |
POWER() |
返回两个参数的幂运算结果,其中一个参数为底,另一个参数为它的指数。 |
RADIANS() |
将参数由角度值转换成弧度值 |
ROUND() |
将所传入数值表达式四舍五入为整数。也可以用来将参数四舍五入到一定的小数位 |
SIN() |
返回参数(以弧度计)的正弦值 |
SQRT() |
返回参数的非负平方根 |
STD() |
返回参数的标准方差值 |
STDDEV() |
返回参数的标准方差值 |
TAN() |
返回参数(以弧度计)的正切值 |
TRUNCATE() |
将数值参数 expr1 的小数位截取到 expr2 位如果 expr2 为0,则结果没有小数位。 |
具体用法:极客学院
汇总数据
我们经常需要汇总数据而不用把它们实际检索出来,为此MySQL提供了专门的函数。使用这些函数,MySQL查询可用于检索数据,以便分析和报表生成。
以下是MySQL的五个聚集函数:
| 函数 | 说明 |
|---|---|
| AVG() | 返回某列的平均值 |
| COUNT() | 返回某列的行数 |
| MAX() | 返回某列的最大值 |
| MIN() | 返回某列的最小值 |
| SUM() | 返回某列值之和 |
标准偏差 MySQL还支持一系列的标准偏差聚集函数。详情戳:MySQL 5.7 Reference Manual
因为上面五个函数都是语义清晰的,因此只讲一些注意事项:
AVG()函数:
只用于单个列 AVG()只能用来确定特定数值列的平均值,而且列名必须作为函数参数给出。为了获得多个列的平均值,必须使用多个AVG()函数。
NULL值 AVG()函数忽略列值为NULL的行。
COUNT()函数的两种使用方法:
- 使用COUNT(*)对表中行的数目进行计数,不管表列中包含的是空值(NULL)还是非空值。
- 使用COUNT(column)对特定列中具有值的行进行计数,忽略NULL值。
MAX()函数:
对非数值数据使用MAX() 虽然MAX()一般用来找出最大的数值或日期值,但MySQL允许将它用来返回任意列中的最大值,包括返回文本列中的最大值。在用于文本数据时,如果数据按相应的列排序,则MAX()返回最后一行。
MIN()函数:
对非数值数据使用MIN() MIN()函数与MAX()函数类似,MySQL允许将它用来返回任意列中的最小值,包括返回文本列中的最小值。在用于文本数据时,如果数据按相应的列排序,则MIN()返回最前面的行。
SUM()函数:
除了统计某一列的变量的和,还可以用来合计计算值。如:
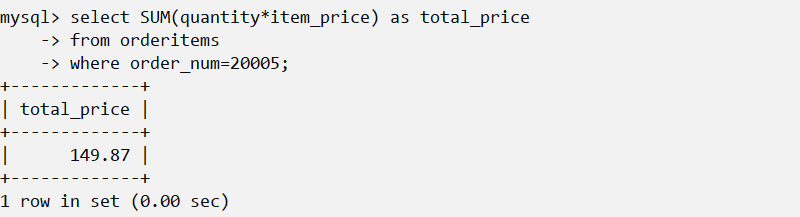
在多个列上进行计算 如上所示,利用标准的算术操作符,所有聚集函数都可用来执行多个列上的计算。
聚集不同值:
对以上的5个聚集函数,都有如下选项:
- 对所有的行执行计算,指定ALL参数或不给参数(因为ALL是默认行为);
- 只包含不同的值,指定DISTINCT参数。
ALL为默认 ALL参数不需要指定,因为它是默认行为。如果不指定DISTINCT,则假定为ALL。
重要:
注意 如果指定列名,则DISTINCT只能用于COUNT()。DISTINCT不能用于COUNT(*),因此不允许使用COUNT(DISTINCT),否则会产生错误。类似地,DISTINCT必须使用列名,不能用
于计算或表达式。
理由想想就知道:COUNT(*)的目的是统计表中有多少行,而DISTINCT选项会忽略掉一些NULL值,是冲突的。同样对于计算或表达式,可能不同的计算式或表达式会产生相同的结果,如果不加考虑的直接去重,会丢失很多数据。
将DISTINCT用于MIN()和MAX() 虽然DISTINCT从技术上可用于MIN()和MAX(),但这样做实际上没有价值。一个列中的最小值和最大值不管是否包含不同值都是相同的。
重要:
取别名 在指定别名以包含某个聚集函数的结果时,不应该使用表中实际的列名。虽然这样做并非不合法,但使用唯一的名字会使你的SQL更易于理解和使用(以及将来容易排除故障)。
聚集函数用来汇总数据。MySQL支持一系列聚集函数,可以用多种方法使用它们以返回所需的结果。这些函数是高效设计的,它们返回结果一般比你在自己的客户机应用程序中计算要快得多。
分组数据
MySQL通过SELECT语句中的GROUP BY子句创建分组。如:
select <variables> from <table> GROUP BY <flag> 其中
一些规定:
- GROUP BY子句可以包含任意数目的列。这使得能对分组进行嵌套,为数据分组提供更细致的控制。例如经常使用的:
group by year, month, day按天分组 - 如果在GROUP BY子句中嵌套了分组,数据将在最后规定的分组上进行汇总。换句话说,在建立分组时,指定的所有列都一起计算(所以不能从个别的列取回数据)。i.e.:
group by year, month, day按天使用聚集函数 - GROUP BY子句中列出的每个列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在SELECT中使用表达式,则必须在GROUP BY子句中指定相同的表达式。 不能使用别名。(应该是说GROUP BY子句中不允许使用列的别名,但是select语句中是可以指定列的别名的)。
- 除聚集计算语句外,SELECT语句中的每个列都必须在GROUP BY子句中给出。
- 如果分组列中具有NULL值,则NULL将作为一个分组返回。如果列中有多行NULL值,它们将分为一组。
- GROUP BY子句必须出现在WHERE子句之后,ORDER BY子句之前。
也就是说,根据我们已经学的MySQL表达式,一套比较完整的流程是:
select var1, var2, COUNT(*) as n
from table
where Condition(var)
group by var1, var2
order by var1, var2 DESC
i.e.:我们必须先筛选,再分组,最后对分组进行排序。
此外:
使用ROLLUP 使用WITH ROLLUP关键字,可以得到每个分组以及每个分组汇总级别(针对每个分组)的值,如下所示:
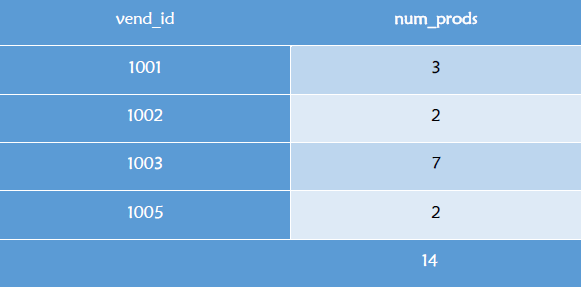
select vend_id, count(*) as num_prods from products group by vend_id with rollup;
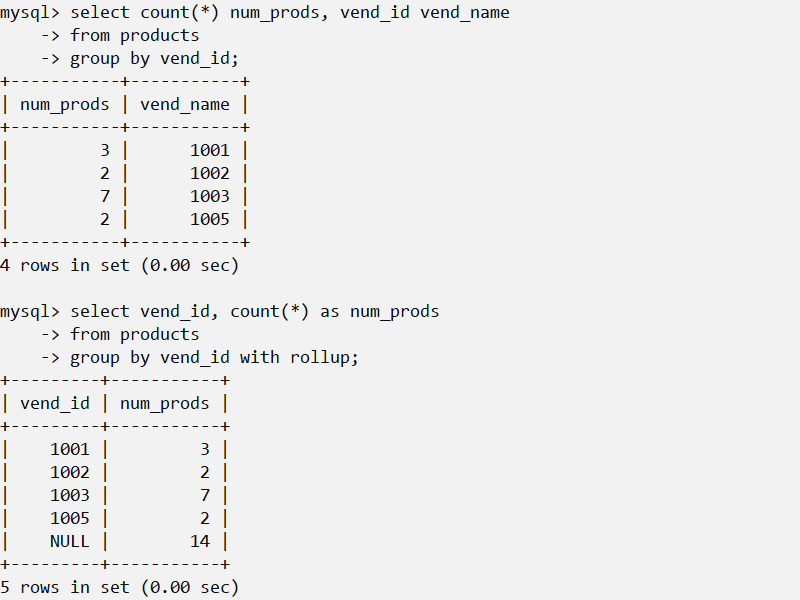
可以看到with rollup选项实际上做的是一个超分组的操作,即对分组的数据再次进行汇总。最后一行的NULL实际上代表为空,效果是这样滴:
那问题就来了,如果本来的分组值里面有个NULL怎么办呢?
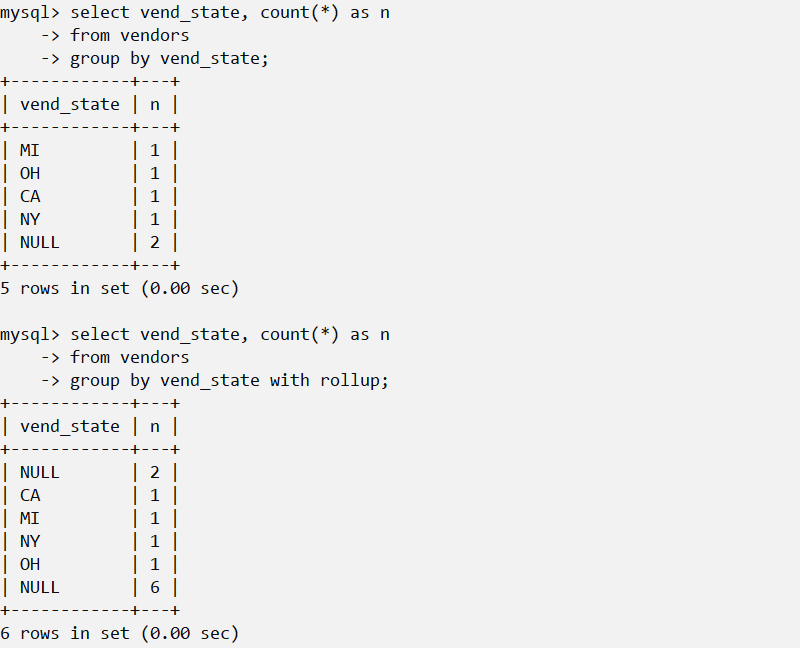
注意,同所有数据分析的工具一样,如果不加with rollup选项,NA值会附加在末尾,而一旦加了with rollup选项,空值会自动调整到第一行。
除了能用GROUP BY分组数据外,MySQL还允许过滤分组,规定包括哪些分组,排除哪些分组。我们已经看到了WHERE子句的作用。
但是,在这个需求下WHERE不能完成任务,因为WHERE过滤指定的是行而不是分组。事实上,WHERE没有分组的概念。那么,不使用WHERE使用什么呢?MySQL为此目的提供了另外的子句,那就是HAVING子句。HAVING非常类似于WHERE。事实上,目前为止所学过的所有类型的WHERE子句都可以用HAVING来替代。唯一的差别是WHERE过滤行,而HAVING过滤分组。
HAVING支持所有WHERE操作符 之前提到过的所有可以在where子句中使用过的条件都可以在
HAVING子句中使用。
HAVING和WHERE的差别 这里有另一种理解方法,WHERE在数据分组前进行过滤,HAVING在数据分组后进行过滤。这是一个重要的区别,WHERE排除的行不包括在分组中。这可能会改变计算值,从而影响HAVING子句中基于这些值过滤掉的分组。
分组与排序

我们经常发现用GROUP BY分组的数据确实是以分组顺序输出的。但情况并不总是这样,它并不是SQL规范所要求的。此外,用户也可能会要求以不同于分组的顺序排序。仅因为你以某种方式分组数据(获得特定的分组聚集值),并不表示你需要以相同的方式排序输出。应该提供明确的ORDER BY子句,即使其效果等同于GROUP BY子句也是如此。
不要忘记ORDER BY 一般在使用GROUP BY子句时,应该也给出ORDER BY子句。这是保证数据正确排序的唯一方法。千万不要仅依赖GROUP BY排序数据。
SELECT子句顺序
SELECT var1, var2...
FROM <table>
WHERE <conditions>
GROUP BY var
HAVING <conditions>
ORDER BY var [DESC]
LIMIT [start,] num
说明:
| 子句 | 说明 | 是否必须使用 |
|---|---|---|
| SELECT | 要返回的列或表达式 | 是 |
| FROM | 从中检索数据的表 | 仅从表中选择数据时使用 |
| WHERE | 行级过滤 | 否 |
| GROUP BY | 分组说明 | 仅在按组计算聚集时使用 |
| HAVING | 组级过滤 | 否 |
| ORDER BY | 输出排序顺序 | 否 |
| LIMIT | 要检索的行数 | 否 |
使用子查询
子查询,即嵌套在其他查询中的查询。
例如:现在需要列出订购物品TNT2的所有客户:
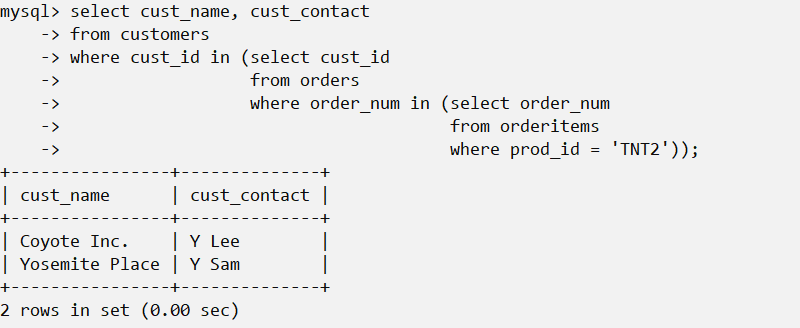
格式化SQL 包含子查询的SELECT语句难以阅读和调试,特别是它们较为复杂时更是如此。如上所示把子查询分解为多行并且适当地进行缩进,能极大地简化子查询的使用。
尤其要注意这个格式化的过程,因为外部查询实际上需要的是内部查询返回一个,分隔的tuple。
可见,在WHERE子句中使用子查询能够编写出功能很强并且很灵活的SQL语句。对于能嵌套的子查询的数目没有限制,不过在实际使用时由于性能的限制,不能嵌套太多的子查询。
虽然子查询一般与IN操作符结合使用,但也可以用于测试等于(=)、不等于(<>)等。
子查询和性能 这里给出的代码有效并获得所需的结果。但是,使用子查询并不总是执行这种类型的数据检索的最有效的方法。
作为计算字段使用子查询
计算字段,即跟着select语句的一些字段,是使用子查询的另外一种方式。
例:假如需要显示customers表中每个客户的订单总数,为此,我们必须执行两个步骤:
- 从customers表中检索客户列表。
- 对于检索出的每个客户,统计其在orders表中的订单数目。
有:
SELECT cust_name,
cust_state,
(SELECT COUNT(*)
FROM orders
WHERE orders.cust_id = customers.cust_id) AS orders
FROM customers
ORDER BY cust_name;
注意这里被嵌套的查询where子句需要使用完全限定的列名。
相关子查询(correlated subquery) 涉及外部查询的子查询。
此外,如上给出的
sql语句并不是最高效的办法。后续会进行改进。
逐渐增加子查询来建立查询 用子查询测试和调试查询很有技巧性,特别是在这些语句的复杂性不断增加的情况下更是如此。用子查询建立(和测试)查询的最可靠的方法是逐渐进行,这与MySQL处理它们的方法非常相同。首先,建立和测试最内层的查询。然后,用硬编码数据建立和测试外层查询,并且仅在确认它正常后才嵌入子查询。这时,再次测试它。对于要增加的每个查询,重复这些步骤。这样做仅给构造查询增加了一点点时间,但节省了以后(找出查询为什么不正常)的大量时间,并且极大地提高了查询一开始就正常工作的可能性。
如上提供了SQL的调试办法。
联结表
将不同表中的数据合并就是联结。
维护引用完整性 重要的是,要理解联结不是物理实体。换句话说,它在实际的数据库表中不存在。联结由MySQL根据需要建立,它存在于查询的执行当中。在使用关系表时,仅在关系列中插入合法的数据非常重要。回到这里的例子,如果在products表中插入拥有非法供应商ID(即没有在vendors表中出现)的供应商生产的产品,则这些产品是不可访问的,因为它们没有关联到某个供应商。为防止这种情况发生,可指示MySQL只允许在products表的供应商ID列中出现合法值(即出现在vendors表中的供应商)。这就是维护引用完整性,它是通过在表的定义中指定主键和外键来实现的。
内连接(自然连接)的两种使用方法:
如果我们要查询供应商所有的商品及其价格,我们可以:
SELECT vend_name, prod_name, prod_price
FROM vendors, products
WHERE vendors.vend_id = products.vend_id
ORDER BY vend_name, prod_name;
还可以:
SELECT vend_name, prod_name, prod_price
FROM vendors INNER JOIN products
ON vendors.vend_id = products.vend_id
ORDER BY vend_name, prod_name;
其中前者是通常的where子句写法,后者明确的表示这是个内连接。通过ON子句传递条件。
特别要注意是:where子句和on子句传递的条件必须不能忘记,否则直接返回一个笛卡尔积。
不要忘了WHERE子句 应该保证所有联结都有WHERE子句,否则MySQL将返回比想要的数据多得多的数据。同理,应该保证WHERE子句的正确性。不正确的过滤条件将导致MySQL返回
不正确的数据。
叉联结 有时我们会听到返回称为叉联结(cross join)的笛卡儿积(cartesian product)的联结类型。
反过来看一下子查询中查询订购产品TNT2的客户那个例子:
# 子查询
SELECT cust_name, cust_contact
FROM customers
WHERE cust_id IN (SELECT cust_id
FROM orders
WHERE order_num IN (SELECT order_num
FROM orderitems
WHERE prod_id = 'TNT2'))
# 内连接
SELECT cust_name, cust_contact
FROM customers, orders, orderitems
WHERE customers, cust_id = orders.cust_id
AND orderitems.order_num = orders.order_num
AND prod_id = 'TNT2';
多做实验 正如所见,为执行任一给定的SQL操作,一般存在不止一种方法。很少有绝对正确或绝对错误的方法。性能可能会受操作类型、表中数据量、是否存在索引或键以及其他一些条件的影响。因此,有必要对不同的选择机制进行实验,以找出最适合具体情况的方法。
创建高级联结
MySQL不仅支持给计算字段取别名,同时也支持给表取别名。这样做主要有以下两个理由:
- 缩短SQL语句;
- 允许单条SELECT语句中多次使用相同的表。
很容易想到的一点是:表别名只在查询执行中使用,与列别名不一样,表别名不返回到客户机。
不同类型的连接:
之前谈到过内连接,这里介绍其他的三种连接: 自连接,自然连接,外连接。其中外连接包括左外连接,右外连接,但是MySQL并没有提供全连接的语法支持。不过是可以通过某些方法模拟出来全连接的。
自连接:
自连接通过给同一张表取别名的方式,多次连接同一张表。并且进行条件运算。如:
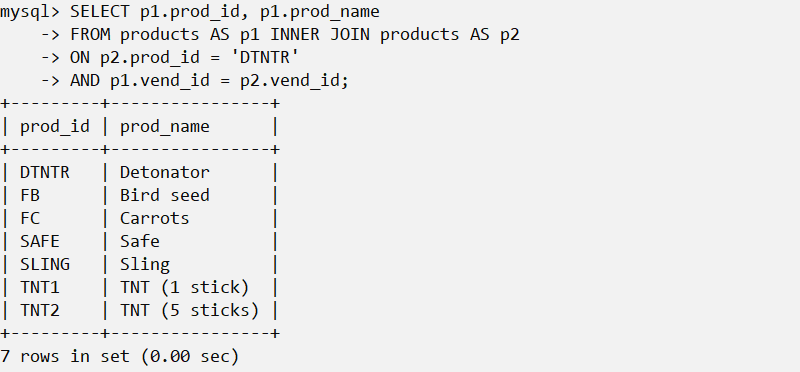
注意: MySQL中进行连接时,如果要选择的计算字段语义不明,必须给定表名限定的字段名。如上所示。同时,既可以使用from <INNER/LEFT/RIGHT> JOIN on...也可以使用from ... where ...。
用自联结而不用子查询 自联结通常作为外部语句用来替代从相同表中检索数据时使用的子查询语句。虽然最终的结果是相同的,但有时候处理联结远比处理子查询快得多。应该试一下两种方法,以确定哪一种的性能更好。
自然连接:
无论何时对表进行联结,应该至少有一个列出现在不止一个表中(被联结的列)。标准的联结(笛卡尔积)返回所有数据,甚至相同的列多次出现。自然联结排除多次出现,使每个列只返回一次。
怎样完成这项工作呢?答案是,系统不完成这项工作,由你自己完成它。自然联结是这样一种联结,其中你只能选择那些唯一的列。这一般是通过对表使用通配符(SELECT *),对所有其他表的列使用明确的子集来完成的。下面举一个例子:
SELECT c.*, o.order_num, o.order_date,
oi.prod_id, oi.quantity, oi.item_price
FROM customers AS c, orders AS o, orderitems AS oi
WHERE c.cust_id = o.cust_id
AND oi.order_num = o.order_num
AND prod_id = 'FB';
外部连接:
SELECT customers.cust_id, orders.order_num
FROM customers LEFT JOIN orders
ON customers.cust_id = orders.cust_id;
MySQL左外连接,右外连接的语法支持分别是 LEFT JOIN和RIGHT JOIN。
没有=操作符 MySQL不支持简化字符=和=*的使用,这两种操作符在其他DBMS中是很流行的。
外部联结的类型 存在两种基本的外部联结形式:左外部联结和右外部联结。它们之间的唯一差别是所关联的表的顺序不同。换句话说,左外部联结可通过颠倒FROM或WHERE子句中表的顺序转换为右外部联结。因此,两种类型的外部联结可互换使用,而究竟使用哪一种纯粹是根据方便而定
此外,聚集函数也可以在各种连接中使用。
使用连接和链接条件:
- 注意所使用的联结类型。一般我们使用内部联结,但使用外部联结也是有效的。
- 保证使用正确的联结条件,否则将返回不正确的数据。
- 应该总是提供联结条件,否则会得出笛卡儿积。
- 在一个联结中可以包含多个表,甚至对于每个联结可以采用不同的联结类型。虽然这样做是合法的,一般也很有用,但应该在一起测试它们前,分别测试每个联结。这将使故障排除更为简单。
组合查询
组合查询/复合查询:或者说,不同查询结果的并(UNION)。
两种情况:
- 在单个查询中从不同的表返回类似结构的数据;
- 对单个表执行多个查询,按单个查询返回数据。
组合查询和多个WHERE条件 多数情况下,组合相同表的两个查询完成的工作与具有多WHERE子句条件的单条查询完成的工作相同。换句话说,任何具有多个WHERE子句的SELECT语句都可以作为一个组合查询给出,在以下段落中可以看到这一点。这两种技术在不同的查询中性能也不同。因此,应该试一下这两种技术,以确定对特定的查询哪一种性能更好。
可用UNION操作符来组合数条SQL查询。利用UNION,可给出多条SELECT语句,将它们的结果组合成单个结果集。例如:筛选价格小于等于5的所有物品的一个列表,而且还想包括供应商1001和1002生产的所有物品(不考虑价格)。虽然可以很简单的用where子句完成,但这里也可以选用UNION操作符:
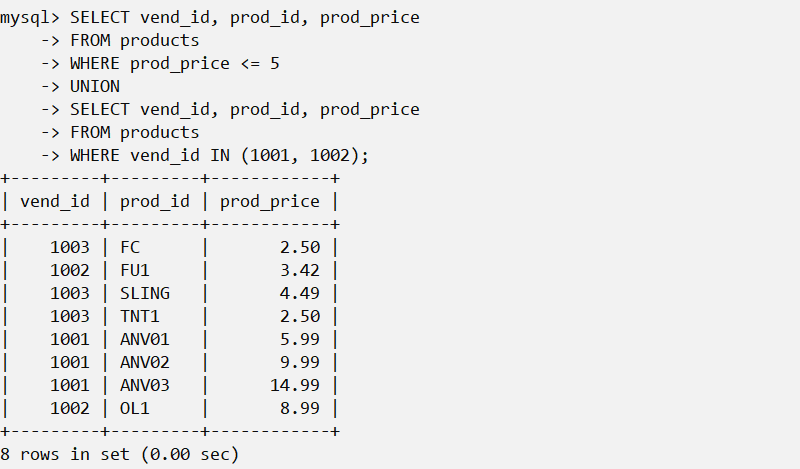
使用UNION操作符的一些规则:
- UNION必须由两条或两条以上的SELECT语句组成,语句之间用关键字UNION分隔(因此,如果组合4条SELECT语句,将要使用3个UNION关键字)。
- UNION中的每个查询必须包含相同的列、表达式或聚集函数(不过各个列不需要以相同的次序列出)。
- 列数据类型必须兼容:类型不必完全相同,但必须是DBMS可以隐含地转换的类型(例如,不同的数值类型或不同的日期类型)。
此外,UNION的默认行为会去重,如果想要覆盖掉这种默认行为,可以:
SELECT vend_id, prod_id, prod_price
FROM products
WHERE prod_price <= 5
UNION ALL
SELECT vend_id, prod_id, prod_price
FROM products
WHERE vend_id IN (1001, 1002)
使用UNION ALL,MySQL不取消重复的行。
UNION与WHERE UNION几乎总是完成与多个WHERE条件相同的工作。UNION ALL为UNION的一种形式,它完成WHERE子句完成不了的工作。如果确实需要每个条件的匹配行全部出现(包括重复行),则必须使用UNION ALL而不是WHERE。
最后,如果想要对UNION的结果排序,只能在最后一行加一行ORDER BY对整个表进行排序。不能以一种方式对一部分排序,以另一种方式对另一部分排序。并且,前面提到过的,可以对不同的表应用组合查询,而不仅限于例子中的单表。
之前在创建高级连接的时候提到过,mysql并没有语法层面的对full join的支持,学完UNION后,我们看看怎样实现一个FULL JOIN:
可能第一次会是这样:
SELECT * FROM t1
LEFT JOIN t2 ON t1.id = t2.id
UNION
SELECT * FROM t1
RIGHT JOIN t2 ON t1.id = t2.id
然后这就没问题了吗?不对,一个比较通用的FULL JOIN是不会自动去重的,所以第二次你可能会写出这样的code:
(The query above works for special cases where a FULL OUTER JOIN operation would not produce any duplicate rows. The query above depends on the UNION set operator to remove duplicate rows introduced by the query pattern. We can avoid introducing duplicate rows by using an anti-join pattern for the second query, and then use a UNION ALL set operator to combine the two sets. In the more general case, where a FULL OUTER JOIN would return duplicate rows, we can do this:)
SELECT * FROM t1
LEFT JOIN t2 ON t1.id = t2.id
UNION ALL
SELECT * FROM t1
RIGHT JOIN t2 ON t1.id = t2.id
WHERE t1.id IS NULL
但是这样就完了吗?不对,可以看到最后一行做了判断t1.id IS NULL,对问题来了,怎么保证t1.id是允许为空的,上面那个查询一定会是语法正确的吗?

参考:
Stack Overflow How to do a FULL OUTER JOIN in MySQL?
Stack Overflow Why does MySQL report a syntax error on FULL OUTER JOIN?
MySQL Reference Manual
全文本搜索
MySQL是一个多引擎架构的关系数据库。但是并非所有的引擎都支持全文本搜索。
并非所有引擎都支持全文本搜索 MySQL支持几种基本的数据库引擎。并非所有的引擎都支持全文本搜索。两个最常使用的引擎为MyISAM和InnoDB,前者支持全文本搜索,而后者不支持。这就是为什么例子中绝大多数表格创建时使用的都是InnoDB , 而有一个样例表(productnotes表)却使用MyISAM的原因。如果你的应用中需要全文本搜索功能,应该记住这一点。
注意,在新版MySQL5.6.24中也允许在InnoDB上建全文本索引了。
那为什么有了通配操作符和正则表达式之后还需要全文本搜索呢?这是因为虽然这些机制非常有用,但有几个重要的限制:
- 性能——通配符和正则表达式匹配通常要求MySQL尝试匹配表中所有行(而且这些搜索极少使用表索引)。因此,由于被搜索行数不断增加,这些搜索可能非常耗时。
- 明确控制——使用通配符和正则表达式匹配,很难(而且并不总是能)明确地控制匹配什么和不匹配什么。例如,指定一个词必须匹配,一个词必须不匹配,而一个词仅在第一个词确实匹配的情况下才可以匹配或者才可以不匹配。(我表示怀疑,正则表达式是万能的)
- 智能化的结果——虽然基于通配符和正则表达式的搜索提供了非常灵活的搜索,但它们都不能提供一种智能化的选择结果的方法。例如,一个特殊词的搜索将会返回包含该词的所有行,而不区分包含单个匹配的行和包含多个匹配的行(按照可能是更好的匹配来排列它们)。类似,一个特殊词的搜索将不会找出不包含该词但包含其他相关词的行。
接下来就是重头戏了:所有这些限制以及更多的限制都可以用全文本搜索来解决。在使用全文本搜索时,MySQL不需要分别查看每个行,不需要分别分析和处理每个词。MySQL创建指定列中各词的一个索引,搜索可以针对这些词进行。这样,MySQL可以快速有效地决定哪些词匹配(哪些行包含它们),哪些词不匹配,它们匹配的频率,等等。
为了进行全文本搜索,必须索引被搜索的列,而且要随着数据的改变不断地重新索引。在对表列进行适当设计后,MySQL会自动进行所有的索引和重新索引。在索引之后,SELECT可与Match()和Against()一起使用以实际执行搜索。
一般在创建表时启用全文本搜索。CREATE TABLE语句接受FULLTEXT子句,给出被索引列的一个逗号分隔的列表。
如:
CREATE TABLE productnotes
(
note_id int NOT NULL AUTO_INCREMENT,
prod_id char(10) NOT NULL,
note_date datetime NOT NULL,
note_text text NULL ,
PRIMARY KEY(note_id),
FULLTEXT(note_text)
) ENGINE=MyISAM;
MySQL 根据子句FULLTEXT(note_text)对该列进行索引。如果需要,也可以索引多个列。
在定义之后,MySQL将会自动维护该索引。在增删改的时候,索引会自动更新。可以在创建表时指定FULLTEXT,也可以稍后指定。
显然,这解决了开头提出的第一个问题--性能。
不要在导入数据时使用FULLTEXT 更新索引要花时间,虽然不是很多,但毕竟要花时间。如果正在导入数据到一个新表,此时不应该启用FULLTEXT索引。应该首先导入所有数据,然后再修改表,定义FULLTEXT。这样有助于更快地导入数据(而且使索引数据的总时间小于在导入每行时分别进行索引所需的总时间)。
如果可以,尽量先导入数据,然后立即建立索引。
全文本索引的三种用途:
基础功能:
利用Match()和Against()两个函数执行全文本搜索,其中Match指定被搜索的列,Against()指定要使用的搜索表达式。注意这里是可以使用对多列使用全文本搜索的。比如对一篇文章进行全文本搜索的时候,我们不光关心它的内容,对标题也会进行全文本搜索。
使用完整的Match() 说明 传递给Match() 的值必须与FULLTEXT()定义中的相同。如果指定多个列,则必须列出它们(而且次序正确)。(好像在现在版本里面只需要传递个Match()的值与定义相同即可,顺序倒没有那么重要了。)
搜索不区分大小写 除非使用BINARY方式,否则全文本搜索不区分大小写(没有找到如何区分大小写的办法)。后续,找到了,建表的时候将字符编码方式从utf8改成utf8bin即可。其余的字符编码方式同理。
那怎么实现开头提出的第三个问题呢?
我们看全文索引怎么对搜索的结果进行排序的。
实例:
SELECT note_text,
Match(note_text) Against('rabbit') AS sequence
FROM productnotes;
结果:
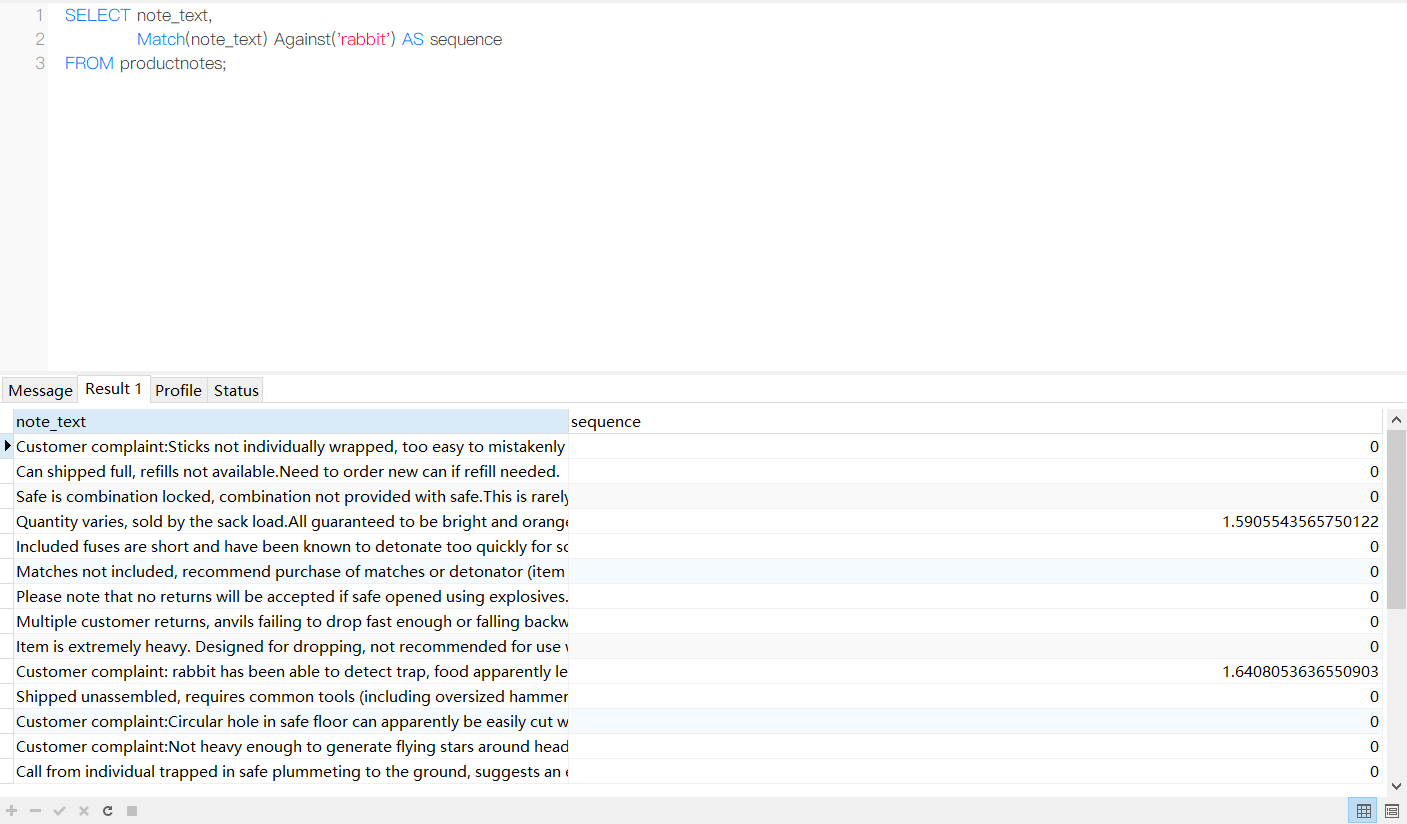
分析:
这里,在SELECT而不是WHERE子句中使用Match()和Against()。这使所有行都被返回(因为没有WHERE子句)。Match()和Against()用来建立一个计算列(别名为rank),此列包含全文本搜索计算出的等级值。等级由MySQL根据行中词的数目、唯一词的数目、整个索引中词的总数以及包含该词的行的数目计算出来。正如所见,不包含词rabbit的行等级为0(因此不被前一例子中的WHERE子句选择)。确实包含词rabbit的两个行每行都有一个等级值,文本中词靠前的行的等级值比词靠后的行的等级值高。
这个例子说明了全文搜索怎么排除行(排除那些相关等级为0的行),怎么排序结果(按等级降序排序)。
排序多个搜索项 如果指定多个搜索项,则包含多数匹配词的那些行将具有比包含较少词(或仅有一个匹配)的那些行高的等级值。
使用查询扩展:
查询扩展用来设法放宽所返回的全文本搜索结果的范围。

.PNG)
敲字员消极怠工。。。
布尔文本搜索:
MySQL全文搜索支持两种模式:默认的称为自然语言模式(IN NATURAL LAGUAGE MODE),再者就是布尔文本搜索(IN BOOLEAN MODE)。
布尔文本搜索提供以下的内容细节:
- 要匹配的词;
- 要排斥的词(如果某行包含这个词,则不返回该行,即使它包含其他指定的词也是如此);
- 排列提示(指定某些词比其他词更重要,更重要的词等级更高);
- 表达式分组;
- 另外一些内容。
即使没有FULLTEXT索引也可以使用 布尔方式不同于迄今为止使用的全文本搜索语法的地方在于, 即使没有定义FULLTEXT索引,也可以使用它。但这是一种非常缓慢的操作(其性能将随着数据量的增加而降低)。(虽然说是这么说,但是还没找到怎么使用的方法)
全文本搜索布尔操作符:
| 操作符 | 描述 |
|---|---|
+ |
包括,这个词必须存在。 |
- |
排除,这个词不能存在。 |
> |
包括并增加排名值。 |
< |
包括并降低排名值。 |
() |
将单词分组成子表达式(允许将其包括,排除,排序等作为一个组)。 |
~ |
否定一个词的排名值。 |
* |
通配符,在结尾的单词,感觉有点像正则里的位置匹配$符号 |
“” |
定义一个短语(与单个单词列表相反,整个短语匹配包含或排除)。 |
举例:

使用要注意的一些地方:
- 在索引全文本数据时,短词被忽略且从索引中排除。短词定义为那些具有3个或3个以下字符的词(如果需要,这个数目可以更改)。
- MySQL带有一个内建的非用词(stopword)列表,这些词在索引全文本数据时总是被忽略。如果需要,可以覆盖这个列表(请参阅MySQL文档以了解如何完成此工作)。
- 许多词出现的频率很高,搜索它们没有用处(返回太多的结果)。因此,MySQL规定了一条50%规则,如果一个词出现在50%以上的行中,则将它作为一个非用词忽略。50%规则不用于IN BOOLEAN MODE。
- 如果表中的行数少于3行,则全文本搜索不返回结果(因为每个词或者不出现,或者至少出现在50%的行中)。
- 忽略词中的单引号。例如,don't索引为dont。
- 不具有词分隔符(包括日语和汉语)的语言不能恰当地返回全文本搜索结果。这个地方又要注意一下,在后续版本中,加入了分词器,使得中文和日文等也能很好的建立全文索引。
没有邻近操作符 邻近搜索是许多全文本搜索支持的一个特性,它能搜索相邻的词(在相同的句子中、相同的段落中或者在特定数目的词的部分中,等等)。MySQL全文本搜索现在还不支持邻近操作符,不过未来的版本有支持这种操作符的计划。
我才说的应该就是分词器了....找了很久也没看到邻近搜索的消息。
接下来看一些其他最近版本的全文本搜索:
首先看一下一些与全文本搜索有关的变量:
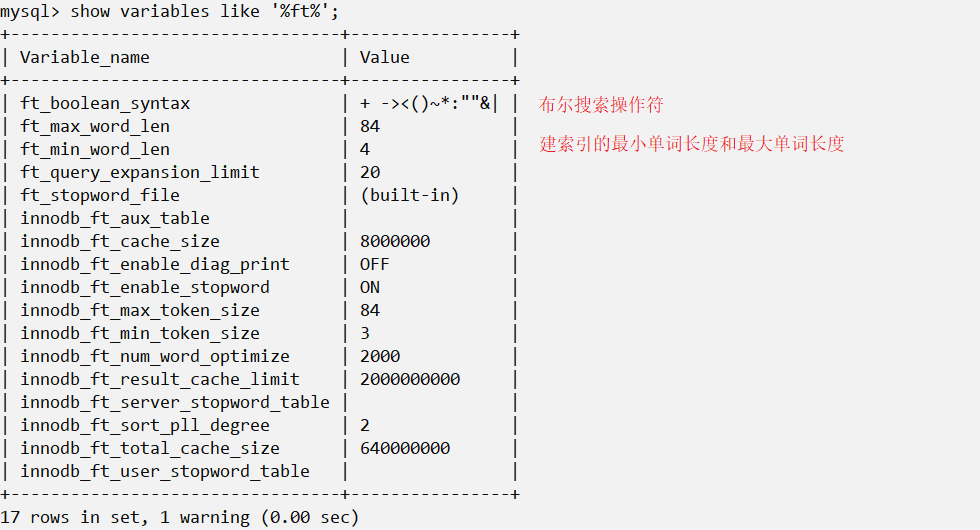
MySQL对全文索引的支持:
- 在 MYSQL 中全文索引是类型为
FULLTEXT的索引.
- 全文索引只能用在
InnoDB或MyISAM表上, 且只能在CHAR,VARCHAR,TEXT类型的列上创建 - MYSQL 提供了内置的基于 ngram 的解析器, 用于支持中韩日文; 还有一个可安装的 MeCAb 解析器插件来支持日文.
FULLTEXT索引可以在创建表时通过CREATE TABLE中定义, 或者在之后ALTER TABLE和CREATE INDEX.- 对于大数据集, 应该将数据插入没有
FULLTEXT索引的表中, 再创建全文索引, 这比将数据插入已创建全文索引的表中更快.
实现细节以及中文搜索:
默认情况下, 搜索是以 不区分大小写 的方式执行的. 要区分大小写, 必须对索引列使用区分大小写或二进制的排序规则. 比如, 使用 utf8mb4 字符集的列可以使用 utf8mb4_0900_as_cs 或 utf8mb4_bin 排序规则.
包含在双引号中的短语, 将按字面值进行匹配. 全文索引会将短语分解为单词, 并在 FULLTEXT 索引中搜索单词. 非单词字符不要求完全匹配. 搜索仅要求匹配项包含与短语完全相同的单词, 并且顺序相同. 例如, 短语 "test phrase" 与文本 "test, phrase" 就匹配.
MYSQL FULLTEXT 实现会将任何 字符序列(字母, 数字, 下划线) 视作一个单词. 这个字符序列中可以包含单引号(), 但在一行中不能多于一个. 所以 aaa'bbb是一个单词, 但aaa''bbb` 就不是一个单词. 同时 FULLTEXT 会将单词开头或结尾的单引号删除.
内置的解析器通过查找某些定界符(delimiter characters)来确定单词的开头或结果. 常见的定界符有空格, 逗号, 句号. 对于单词之间没有定界符分隔的语言, 例如中文, 内置的解析器就无法确定单词的开始或结束位置.
对于这种情况, 为了将这些语言中的单词添加到全文索引中, 有两种方式处理.
在全文索引中, 某些单词会被忽略掉:
- 任何太短的单词. 全文索引的默认最小单词长度在 InnoDB 是三个字符, 在 MyISAM 中是四个字符. 这个特性对 ngram 解析器不适用, ngram 解析器中单词长度由
ngram_token_size选项确定. - 在 stopwords 中的单词将被忽略.(最开始的截图中有介绍)
集合和查询中的每个正确的单词都被根据其在集合或查询中的重要性进行加权. 类似于 TF-IDF. 在多数文档中出现的单词权重比较低. 在所有文档中较少出现的单词权重较高.
布尔搜索:
布尔型的全文搜索支持以下运算符:
+前导或尾随的加号表示单词必须出现在返回的每一行中. InnoDB 仅支持前导的加号.-前导或尾随的减号表示单词不能再返回的任何行中出现. InnoDB 仅支持前导的减号.-仅能排除其他条件搜索到的行. 仅有-会返回空的结果.- (没有操作符) 默认情况, 该单词为可选, 但包含该单词的行评分较高.
@distance仅用于 InnoDB 表. 测试两个或多个单词出现的距离是否在 distance 的值之内. distance 的单位是单词的个数. 使用双引号指定要比较的单词.MATCH(col1) AGAINST('"word1 word2 word3" @8' IN BOOLEAN MODE)word1, word2, word3 之间的距离(单词数)在 8 之内.>``<用于修改单词对所在行的相关性的贡献度.()括号用于将单词分组为子表达式. 括号可以嵌套.~前导的 ~ 表示否定运算符, 使得单词对行的相关性的贡献度为负数. 这对于标记噪音字符很有用. 包含这类单词的行的相关性低于其他行, 但不完全排除.*星号用作截断(通配符)运算符. 当一个单词使用截断符指定时, 即使它太短或者在 stopwords 列表中, 也不会被忽略."包含在引号中的短语, 将按字面值进行匹配.
下面是几个例子:
'apple banana'返回至少包含其中一个单词的行.'+apple ~macintosh'返回包含单词 apple 的行, 如果行中有 macintosh, 它的评级会更低.- `'+apple +(>turnover 返回行中同时有 apple 和 turnover, 或者同时有 apple 和 strudel 的行. apple 和 turnover 的行, 比 apple 和 strudel 的行优先级高.
apple*返回单词以 apple 开头的行, 例如 “apple”, “apples”, “applesauce”, “applet”.'"some words"'返回行中明确包含短语 "some words" 的行, 可以是 “some words of wisdom” 但不能是 “some noise words”.
InnoDB 上的全文搜索是建立在 Sphinx 全文搜索引擎上的, 算法是基于 BM25 和 TF-IDF 排名算法.
相关性排名的计算方式
# 计算 IDF 逆文档频率
${IDF} = log10( ${total_records} / ${matching_records} )
# 文档多次包含一个单词时
${TF} * ${IDF}
# 单个单词的相关性, 不知道为什么要多乘次 ${IDF}
${rank} = ${TF} * ${IDF} * ${IDF}
# 多个单词的相关性
${rank} = ${TF} * ${IDF} * ${IDF} + ${TF} * ${IDF} * ${IDF}
ngram 解析器
一个 ngram 是 n 个字符的连续序列. ngram 解析器将文本序列标记为连续的 n 字符序列. 对于文本序列 "abcd" 可以使用 ngram 解析器标记为不同的 n 版本:
n=1: 'a', 'b', 'c', 'd'
n=2: 'ab', 'bc', 'cd'
n=3: 'abc', 'bcd'
n=4: 'abcd'
ngram 全文解析器是内置的服务器插件, 启动服务器时会自动加载该插件.
配置 token size
ngram 解析器默认的 ngram token size 是 2(bigram).
使用 ngram_token_size 配置选项设置 token size, 可配置的最小值是 1, 最大值是 10. 通常将 ngram_token_size 配置为你想要搜索的最大 token 的长度.
可以在启动的时候设置:
mysqld --ngram_token_size=2
或者在配置文件中设置:
[mysqld]
ngram_token_size=2
查看当前配置:
show variables like '%ngram%';
使用 ngram 解析器创建 FULLTEXT 索引
CREATE TABLE articles2 (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT,
FULLTEXT (title,body) WITH PARSER ngram
) ENGINE=InnoDB CHARACTER SET utf8mb4;
插入些测试数据:
SET NAMES utf8mb4;
INSERT INTO articles2 (title,body) VALUES
('数据库管理','在本教程中我将向你展示如何管理数据库'),
('数据库应用开发','学习开发数据库应用程序');
在表 INFORMATION_SCHEMA.INNODB_FT_INDEX_CACHE 中查看 tokenized data:
SET GLOBAL innodb_ft_aux_table="test/articles2";
SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_INDEX_CACHE ORDER BY doc_id, position;
搜索查询:
select * from articles2 where match(title,body) against ("开发");
修改已存在的表:
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,
title VARCHAR(200),
body TEXT
) ENGINE=InnoDB CHARACTER SET utf8;
ALTER TABLE articles ADD FULLTEXT INDEX ft_index (title,body) WITH PARSER ngram;
# Or:
CREATE FULLTEXT INDEX ft_index ON articles (title,body) WITH PARSER ngram;
其他细节
ngram 解析器会在解析时消除空格.
对于 stopwords, ngram 解析器会排除包含 stopwords 的 token. 比如 stopwords 包含逗号, "a,b" 会在 n=2 时解析为 "a," 和 ",b", 这两个 token 都会被排除. stopwords 中长度大于 ngram_token_size 的单词, 将会被忽略.
对于自然语言搜索, 搜索字符串将会被转换为 ngram token 的并集, 比如 "abc" 会被转换为 "ab" 和 "bc".
对于布尔搜索, 搜索字符串将会被转换为 ngram phrase search. 比如 "abc" 会被转换为 ""ab bc"". 给定两个文档, 一个包含 'ab', 另一个包含 'abc', 搜索短语 ""ab bc"" 只会匹配包含 'abc' 的文档.
通配符搜索可能返回意外的结果. 以下行为适用:
- 如果一个通配符搜索的前缀项小于 ngram_token_size, 查询会返回所有 ngram token 以前缀开始的行. 比如 n=2 时, 搜索 "a*" 会返回所有 ngram token 中以 "a" 开头的行.
- 如果一个通配符搜索的前缀项大于 ngram_token_size, 前缀项会被转换为 ngram phrase, 并且忽略通配符. 比如 n=2 时, "abc*" 通配符搜索会被转换为 "ab bc".
phrase search 会被转换为 ngram phrase search. 比如搜索短语 "abc" 会被转换为 "ab bc", 返回包含 "abc" 或 "ab bc" 的文档. 搜索短语 "abc def" 会被转换为 "ab bc de ef", 返回包含 "abc def" 或 "ab bc de ef" 的文档. 文档包含 "abcdef" 的却不会返回.
最后这个真是迷惑行为大赏, 还是看个例子好了.
INSERT INTO articles2 (title,body) VALUES ('abcdef','在本教程中我将向你展示如何管理数据库');
普通搜索是有数据的:
select * from articles2 where match(title,body) against ('abc def' IN BOOLEAN MODE);
短语搜索没有数据, 注意用 双引号 引起来的表示短语:
select * from articles2 where match(title,body) against ('"abc def"' IN BOOLEAN MODE);
然后切换到自然语言搜索, 两种方式都是有结果的:
select * from articles2 where match(title,body) against ('abc def');
select * from articles2 where match(title,body) against ('"abc def"');
参考:
官方文档
知乎
插入数据
插入数据通常有以下几种形式:
- 插入完整的行;
- 插入行的一部分;
- 插入多行;
- 插入某些查询的结果
插入及系统安全 可针对每个表或每个用户,利用MySQL的安全机制禁止使用INSERT语句
插入完整的行:
INSERT INTO <table> VALUES(NULL/num/string/...)
比如:
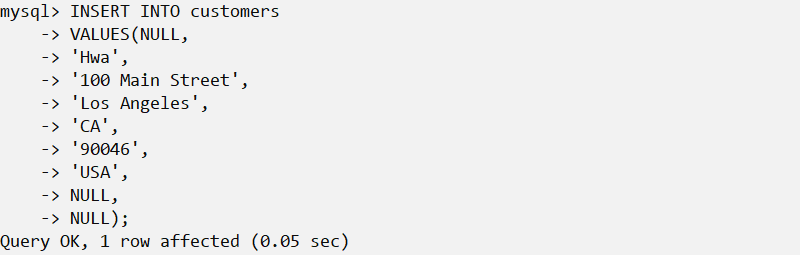
分析:
此例子插入一个新客户到customers表。存储到每个表列中的数据在VALUES子句中给出,对每个列必须提供一个值。如果某个列没有值(如上面的cust_contact和cust_email列),应该使用NULL
值(假定表允许对该列指定空值)。各个列必须以它们在表定义中出现的次序填充。第一列cust_id也为NULL。这是因为每次插入一个新行时,该列由MySQL自动增量。你不想给出一个值(这是MySQL的工作),又不能省略此列(如前所述,必须给出每个列),所以指定一个NULL值(它被
MySQL忽略,MySQL在这里插入下一个可用的cust_id值)。
可以看到,上面的SQL语句极其的不健壮,如果列中的次序发生改变,难免会出现安全问题,所以可以考虑用如下的方式插入记录。
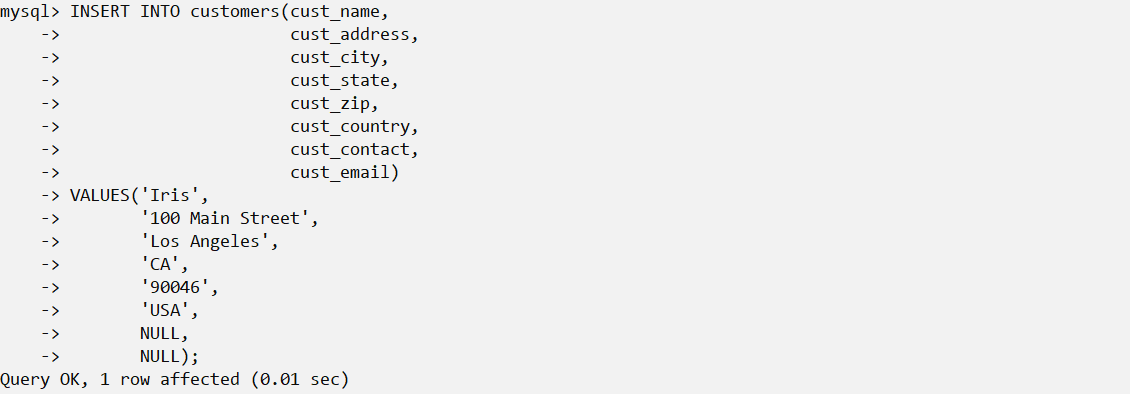
总是使用列的列表 一般不要使用没有明确给出列的列表的INSERT语句。使用列的列表能使SQL代码继续发挥作用,即使表结构发生了变化。
仔细地给出值 不管使用哪种INSERT语法,都必须给出VALUES的正确数目。如果不提供列名,则必须给每个表列提供一个值。如果提供列名,则必须对每个列出的列给出一个值。如果不这样,将产生一条错误消息,相应的行插入不成功。
省略列 如果表的定义允许,则可以在INSERT操作中省略某些列。省略的列必须满足以下某个条件。
该列定义为允许NULL值(无值或空值)。
在表定义中给出默认值。这表示如果不给出值,将使用默认值。
如果对表中不允许NULL值且没有默认值的列不给出值,则
MySQL将产生一条错误消息,并且相应的行插入不成功。
提高整体性能 数据库经常被多个客户访问,对处理什么请求以及用什么次序处理进行管理是MySQL的任务。INSERT操作可能很耗时(特别是有很多索引需要更新时),而且它可能降低等待处理的SELECT语句的性能。如果数据检索是最重要的(通常是这样),则你可以通过在INSERT和INTO之间添加关键字LOW_PRIORITY,指示MySQL降低INSERT语句的优先级,如下所示:顺便说一下,这也适用于马上要介绍的UPDATE和DELETE语句。
插入多个行:
显然,第一种方法是:使用多条插入语句,甚至一次提交他们,每条语句间以一个分号结束:

或者,在列名和次序相同的情况下,组合各语句:

注意:VALUES之间以逗号分隔。
提高INSERT的性能 此技术可以提高数据库处理的性能,因为MySQL用单条INSERT语句处理多个插入比使用多条INSERT语句快。
插入检索出的数据:
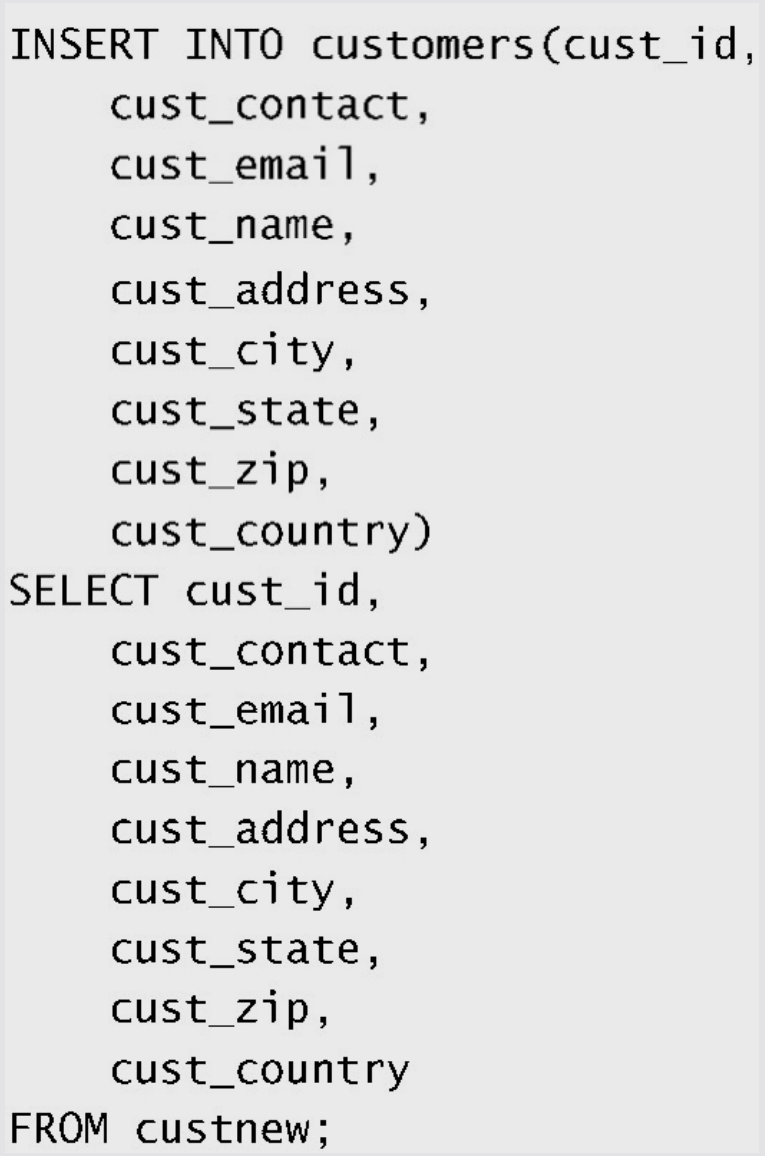
注意:这里导入了cust_id,所以插入的时候需要保证cust_id的值不会重复。当然,也可以根本不关心这一列。
INSERT SELECT中的列名 为简单起见,这个例子在INSERT和SELECT语句中使用了相同的列名。但是,不一定要求列名匹配。事实上,MySQL甚至不关心SELECT返回的列名。它使用的是列的位置,因此SELECT中的第一列(不管其列名)将用来填充表列中指定的第一个列,第二列将用来填充表列中指定的第二个列,如此等等。这对于从使用不同列名的表中导入数据是非
常有用的。
更新和删除数据
更新和删除数据都有两种方式:
- 操作表中特定的行
- 操作表中所有的行
不要省略WHERE子句 因为UPDATE和DELETE都涉及到更改存储的数据,并且MySQL中是不存在undo操作的。因此一定要显式的给出WHERE子句,除非的确打算对整个表进行操作。
同样,两者因为都是对数据更改的不可逆操作,因此可以通过给不同的用户赋予不同的权限,保证操作的安全性。
UPDATE语句的组成:
- 要更新的表
- 列名和它们的新值
- 确定要更新的行和过滤条件
例如:现在需要更新10005客户的邮件信息和名字:
UPDATE customers
SET cust_name = 'The Fudds',
cust_email = 'elmer@fudd.com'
WHERE cust_id = 10005;
可以看到,需要更新多个记录时只需要将key-value对用逗号分开。
此外,UPDATE子句中给定的条件当然可以指定为单个值,多个值,范围甚至是子查询等。
IGNORE关键字 如果用UPDATE语句更新多行,并且在更新这些行中的一行或多行时出一个现错误,则整个UPDATE操作被取消(错误发生前更新的所有行被恢复到它们原来的值)。为了 即使是发生错误,也继续进行更新,可使用IGNORE关键字,如下所示:
UPDATE IGNORE customers…
而删除指定行某几列的值的时候,只需要将指定列设置为NULL即可。
DELETE语句的组成:
- 要删除的数据来源表
- 确定要删除的行的过滤条件
例如:现在需要从customers表中删除cust_id为10006的行:
DELETE FROM customers
WHERE cust_id = 10006;
注意DELETE语句不需要列名或通配符。DELETE删除整行而不是删除列。
删除表的内容而不是表 DELETE语句从表中删除行,甚至是删除表中所有行。但是,DELETE不删除表本身。
更快的删除 如果想从表中删除所有行,不要使用DELETE。可使用TRUNCATE TABLE语句,它完成相同的工作,但速度更快(TRUNCATE实际是删除原来的表并重新创建一个表,而不
是逐行删除表中的数据)。
注意:如果UPDATE和DELETE语句不带WHERE子句,则都是对全表进行操作,这是很危险的。
一些推荐的原则:
- 除非确实打算更新和删除每一行,否则绝对不要使用不带WHERE子句的UPDATE或DELETE语句。
- 保证每个表都有主键,尽可能像WHERE子句那样使用它(可以指定各主键、多个值或值的范围)。
- 在对UPDATE或DELETE语句使用WHERE子句前,应该先用SELECT进行测试,保证它过滤的是正确的记录,以防编写的WHERE子句不正确。
- 使用强制实施引用完整性的数据库,这样MySQL将不允许删除具有与其他表相关联的数据的行。
对于最后一条是怎么理解的呢?不妨我们删除一行试一哈:

没错,根本删除不了。
小心使用 MySQL没有撤销(undo)按钮。应该非常小心地使用UPDATE和DELETE,否则你会发现自己更新或删除了错误的数据。
结语:
2020.05.01-2020.05.03,花了三天终于看完了MySQL的增删改查和写完了前20章总结的笔记,挑战极限!是一本很好的MySQL入门书籍,后续应该会看《高性能MySQL》吧。不打算继续写读书笔记了,效率实在比较低。希望能晚上看完最后10章的内容。Code is Power!
参考书目:
《MySQL必知必会》