从零学数据库mysql--SQL语言,
#SQL语言
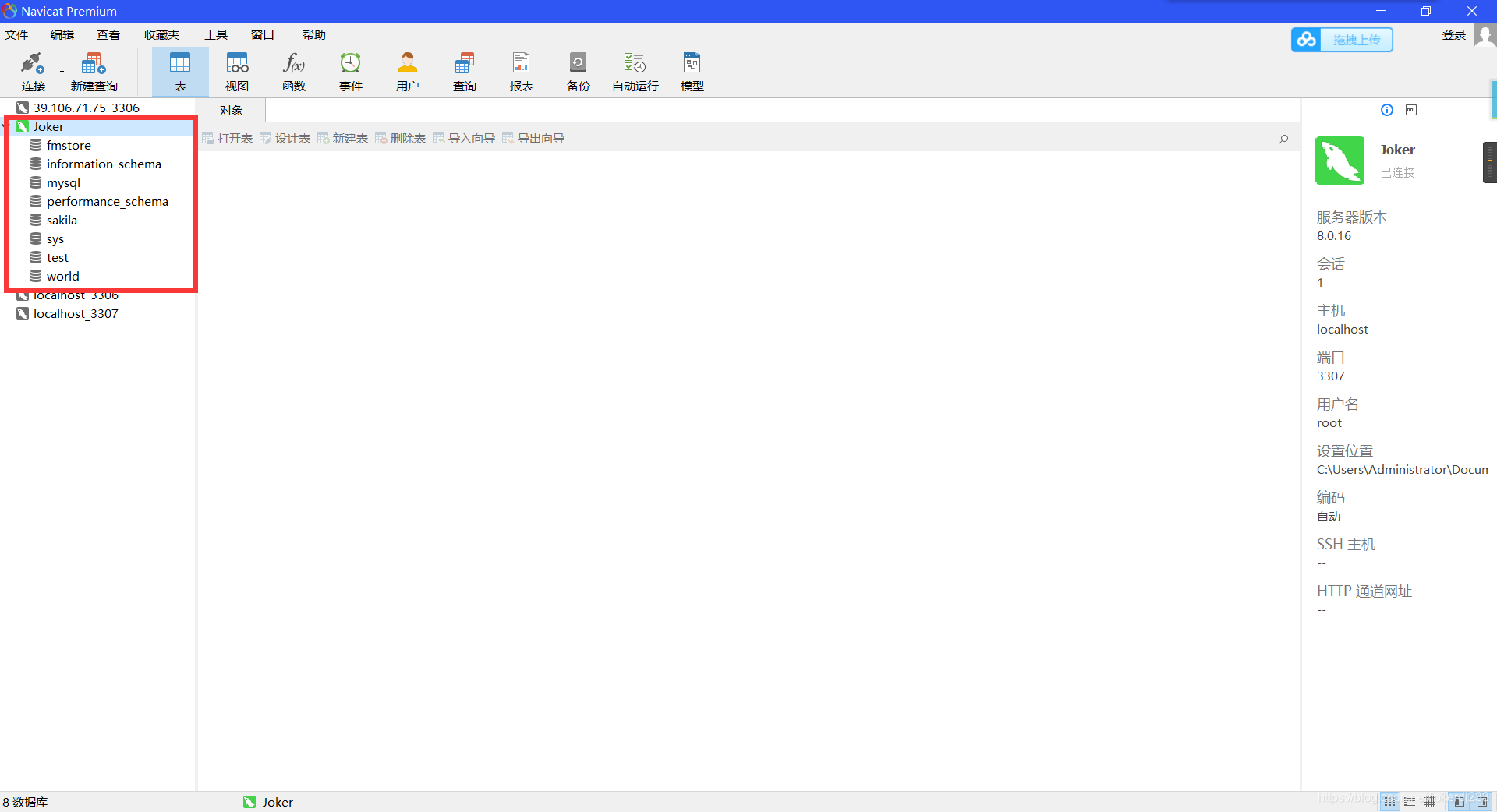
使用Navicate图形化界面工具
官网地址:http://www.navicat.com.cn/download/direct-download?product=navicat_mysql_cs_x64.exe&location=1&support=Y 网盘地址: https://pan.baidu.com/s/1_z9TbieMX9Kemnyj5WWrBQ 提取码:4dgw
字符集
1. 字符集的由来:
2. ASSCII
一套文字符号及其编码,比较规则 的集合。 20世纪60年代初。美国标准化组织ANSI发布了第一个字符集。ASCII
后来又进一步变成了国际标准ISO-646
2. unicode
3. UTF-16
4. UTF-8
5. 汉字的一些常见字符集
什么是SQL
sql功能分类
1. DDL:数据定义语言
用来定义数据库对象:创建库,表,列等。
2. DML:数据操作语言
用来操作数据库表中的记录
3. DQL:数据查询语言
用来查询数据
4. DCL:数据控制语言
用来定义访问权限和安全级别
SQL数据类型
MySQL中定义数据字段的类型对你数据库的优化是非常重要的。
MySQL支持所有标准SQL数值数据类型。
MySQL支持多种类型,大致可以分为三类:
1. 数值类型
一套文字符号及其编码,比较规则 的集合。 20世纪60年代初。美国标准化组织ANSI发布了第一个字符集。ASCII 后来又进一步变成了国际标准ISO-646
sql功能分类
1. DDL:数据定义语言
用来定义数据库对象:创建库,表,列等。
2. DML:数据操作语言
用来操作数据库表中的记录
3. DQL:数据查询语言
用来查询数据
4. DCL:数据控制语言
用来定义访问权限和安全级别
SQL数据类型
MySQL中定义数据字段的类型对你数据库的优化是非常重要的。
MySQL支持所有标准SQL数值数据类型。
MySQL支持多种类型,大致可以分为三类:
1. 数值类型
用来定义数据库对象:创建库,表,列等。
用来操作数据库表中的记录
用来查询数据
用来定义访问权限和安全级别
MySQL中定义数据字段的类型对你数据库的优化是非常重要的。 MySQL支持所有标准SQL数值数据类型。
MySQL支持多种类型,大致可以分为三类:
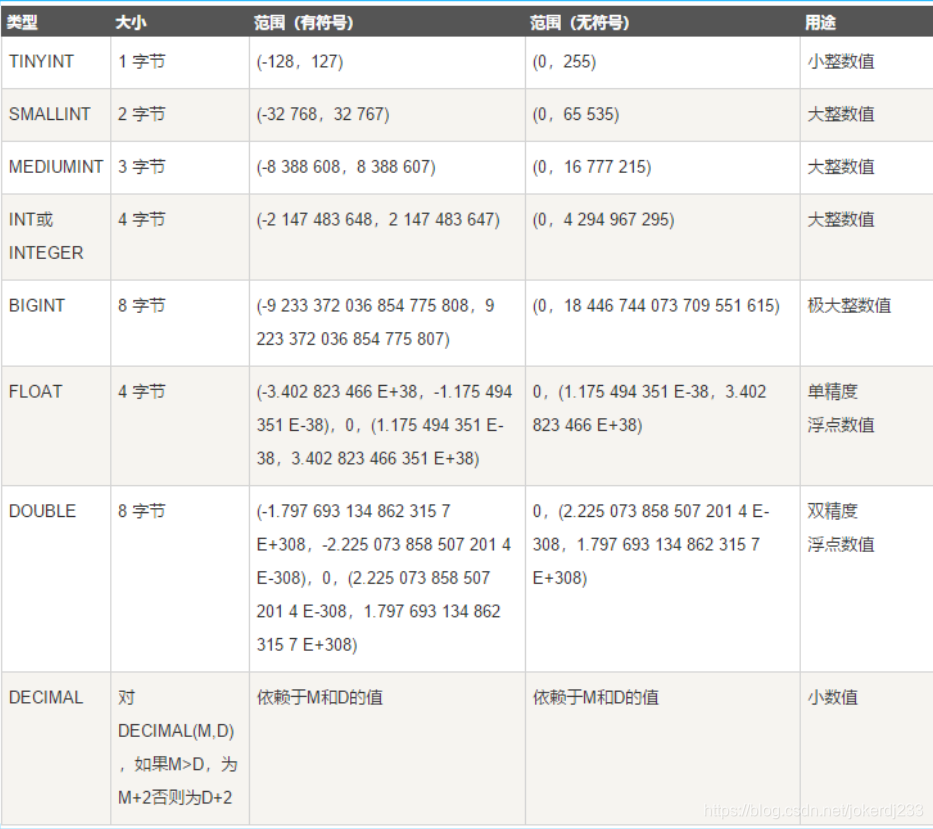
1. 数值类型
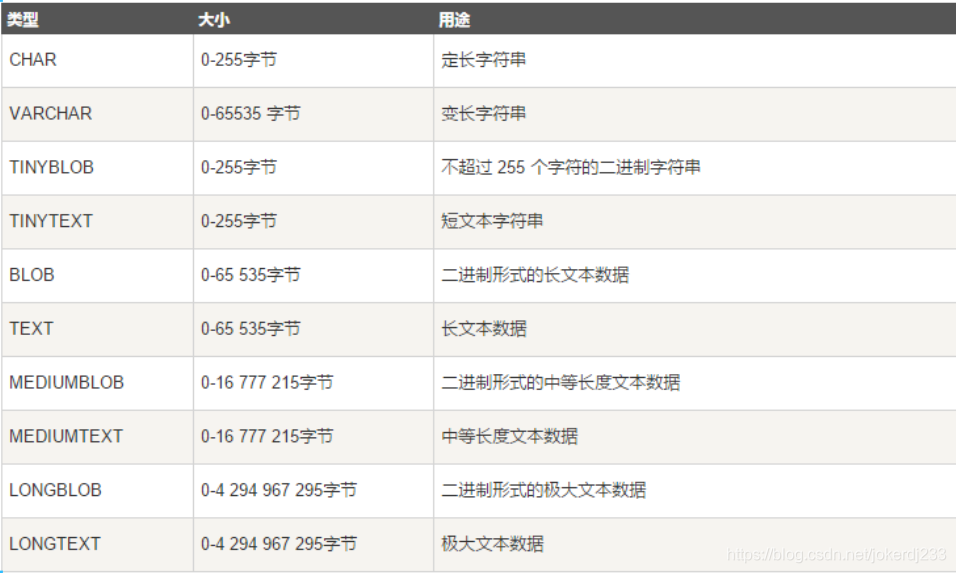
2. 字符串类型
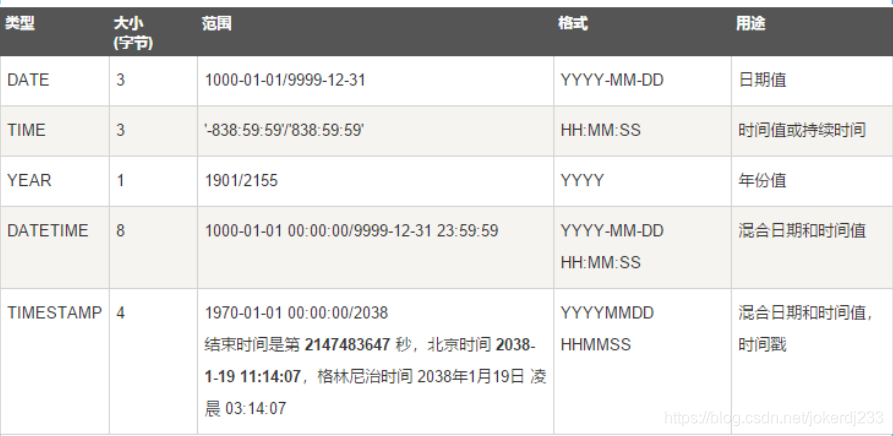
3. 日期和时间类型
常用数据类型
在mysql中,字符串类型和日期类型都要用单引号括起来。'Joker' '2020-01-01'
SQL语句
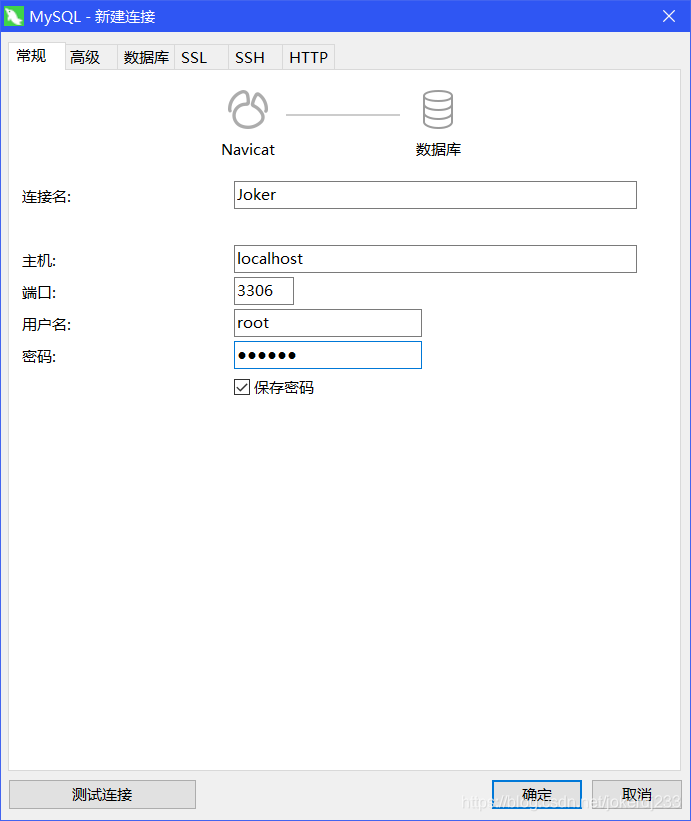
使用Navicate图形化界面工具
连接数据库:
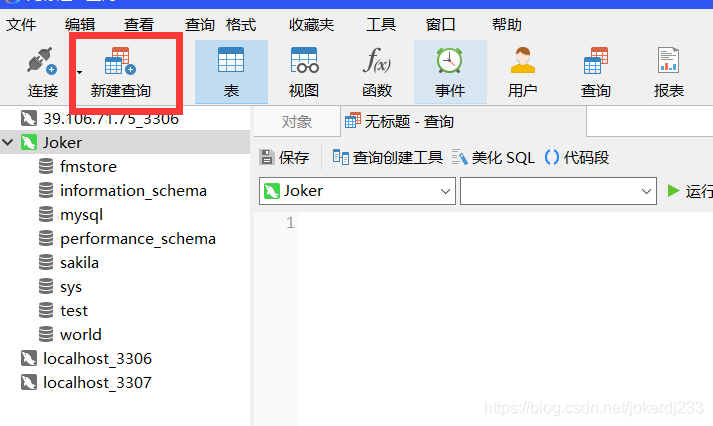
DDL:数据定义语言
1. 创建数据库
create database 数据库名 character set utf8;
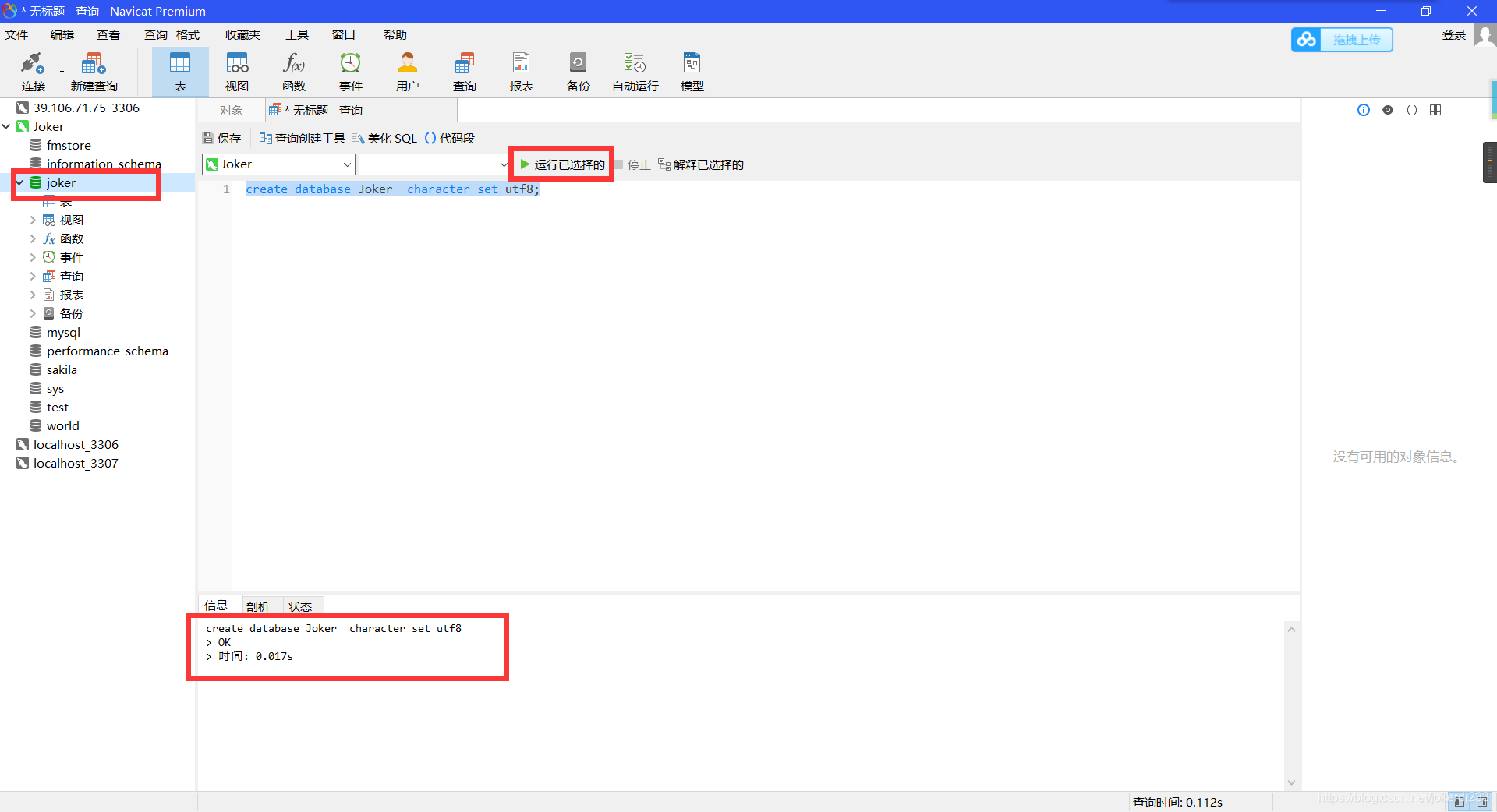
2. 创建学生表
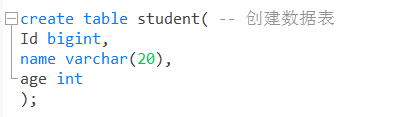
use joker;
create table student( -- 创建数据表
Id bigint,
name varchar(20),
age int
);


3. 添加一列

ALTER TABLE 表名 ADD 列名 数据类型;
4. 查看表的字段信息
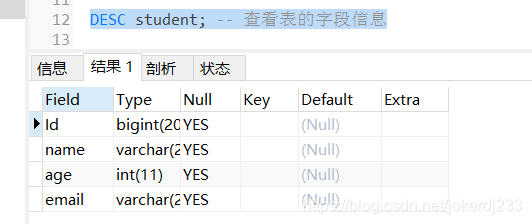
DESC 表名;
5. 修改一个表的字段类型

ALTER TABLE 表名 MODIFY 字段名 数据类型;
6. 删除一列

ALTER TABLE 表名 DROP 字段名;
7. 修改表名
RENAME TABLE 原始表名 TO 要修改的表名;
8. 查看表的创建细节

SHOW CREATE TABLE 表名;
9. 修改表的列名

ALTER TABLE 表名 CHANGE 原始列名 新列名 数据类型;
10. 删除表

DROP TABLE 表名;
1. 修改表的字符集为gbk

ALTER TABLE 表名 CHARACTER SET 字符集名称;
DML:数据操作语言
1. 查询表中的所有数据

SELECT * FROM 表名;
2. 插入操作

INSERT INTO 表名(列名1,列名2 ...)VALUE (列值1,列值2...);
注意事项:
批量插入

INSERT INTO 表名(列名1,列名2 ...)VALUES (列值1,列值2...),(列值1,列值2...);
3. 更新操作
UPDATE 表名 SET 列名1=列值1,列名2=列值2 ... WHERE 列名=值
update students set age=20
- 把姓名为小键的年龄改为18

update students set age=18 where name='小键';
- 把小吴的年龄在原来基础上加1岁

update students set age=age+1 where name='小吴';
- 修改数据库密码 mysql8之前:
use mysql;
update mysql.user set authentication_string=password('123456') where user='root' and Host = 'localhost';
flush privileges;刷新MySQL的系统权限相关表
mysql8:
ALTER USER 'root'@'localhost' IDENTIFIED BY '新密码';
使用mysqladmin修改密码:
mysqladmin -u root -p password 123456
4. 删除操作
DELETE FROM 表名 【WHERE 列名=值】
TRUNCATE TABLE 表名;
DELETED 与TRUNCATE的区别
DQL:数据查询语言
1. 查询所有列
SELECT * FROM 表名;
2. 结果集
数据库执行DQL语句不会对数据进行改变,而是让数据库发送结果集给客户端。 结果集:
3. 查询指定列的数据
SELECT 列名1,列表2... FROM 表名;
4. 条件查询
条件查询就是在查询时给出WHERE子句,在WHERE子句中可以使用一些运算符及关键字:
SELECT * FROM students WHERE gender='男' AND age=20;
- 查询学号为1001 或者 名为zs的记录
SELECT * FROM students WHERE id ='1001' OR name='zs';
- 查询学号为1001,1002,1003的记录
SELECT * FROM students WHERE id='1001' OR id='1002' OR 1001='1003';
SELECT * FROM students WHERE id IN('1001','1002','1003');
- 查询年龄为null的记录
SELECT * FROM students WHERE age IS NULL;
- 查询年龄在18到20之间的学生记录
SELECT * FROM students WHERE age>=18 AND age<=20;
SELECT * FROM students WHERE age BETWEEN 18 AND 20;
- 查询性别非男的学生记录
SELECT * FROM students WHERE gender !='男';
- 查询姓名不为null的学生记录
SELECT * FROM students WHERE name IS NOT NULL;
5. 模糊查询
根据指定的关键进行查询, 使用LIKE关键字后跟通配符 通配符:
_ :任意一个字符 %:任意0~n个字符
SELECT * FROM students WHERE name LIKE '_____';
-- 模糊查询必须使用LIKE关键字。其中 “_”匹配任意一个字母,5个“_”表示5个任意字母。
- 查询姓名由5个字母构成,并且第5个字母为“s”的学生记录
SELECT * FROM students WHERE name LIKE '____s';
- 查询姓名以“m”开头的学生记录
SELECT * FROM students WHERE name LIKE 'm%';
-- 其中“%”匹配0~n个任何字母。
- 查询姓名中第2个字母为“u”的学生记录
SELECT * FROM students WHERE name LIKE '_u%';
- 查询姓名中包含“s”字母的学生记录
SELECT * FROM stu WHERE name LIKE '%s%';
6. 字段控制查询
SELECT DISTINCT name FROM students;
- 把查询字段的结果进行运算,必须都要是数据型
SELECT *,字段1+字段2 FROM 表名;
列有很多记录的值为NULL, 因为任何东西与NULL相加结果还是NULL,所以结算结果可能会出现NULL。 下面使用了把NULL转换成数值0的函数IFNULL:
SELECT *,age+IFNULL(score,0) FROM students;
- 对查询结果起别名
在上面查询中出现列名为sx+IFNULL(yw,0),这很不美观,现在我们给这一列给出一个别名,为total:
SELECT *, yw+IFNULL(sx,0) AS total FROM score;
SELECT *, yw+IFNULL(sx,0) total FROM score; -- 省略 AS
7. 排序
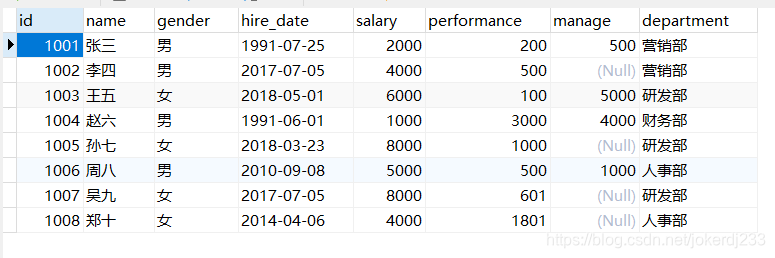
创建表:
CREATE TABLE `employee` (
`id` int(11) NOT NULL,
`name` varchar(50) DEFAULT NULL,
`gender` varchar(1) DEFAULT NULL,
`hire_date` date DEFAULT NULL,
`salary` decimal(10,0) DEFAULT NULL,
`performance` double(255,0) DEFAULT NULL,
`manage` double(255,0) DEFAULT NULL,
`department` varchar(255) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
INSERT INTO `employee` VALUES (1001, '张三', '男', '1991-7-25', 2000, 200, 500, '营销部');
INSERT INTO `employee` VALUES (1002, '李四', '男', '2017-7-5', 4000, 500, NULL, '营销部');
INSERT INTO `employee` VALUES (1003, '王五', '女', '2018-5-1', 6000, 100, 5000, '研发部');
INSERT INTO `employee` VALUES (1004, '赵六', '男', '1991-6-1', 1000, 3000, 4000, '财务部');
INSERT INTO `employee` VALUES (1005, '孙七', '女', '2018-3-23', 8000, 1000, NULL, '研发部');
INSERT INTO `employee` VALUES (1006, '周八', '男', '2010-9-8', 5000, 500, 1000, '人事部');
INSERT INTO `employee` VALUES (1007, '吴九', '女', '2017-7-5', 8000, 601, NULL, '研发部');
INSERT INTO `employee` VALUES (1008, '郑十', '女', '2014-4-6', 4000, 1801, NULL, '人事部');
对查询的结果进行排序 使用关键字ORDER BY 排序类型
SELECT *FROM employee ORDER BY salary ASC;
- 查询所有雇员,按月薪降序排序,如果月薪相同时,按编号升序排序
SELECT * FROM employee ORDER BY salary DESC, id ASC;
8.聚合函数
对查询的结果进行统计计算 常用聚合函数:
1. COUNT
SELECT COUNT(*) AS total_record FROM employee;
- 查询员工表中有绩效的人数
SELECT COUNT(performance) FROM employee;
- 查询员工表中月薪大于2500的人数:
SELECT COUNT(*) FROM employee WHERE salary > 2500;
- 统计月薪与绩效之和大于5000元的人数:
SELECT COUNT(*) FROM employee WHERE salary+IFNULL(performance,0) > 5000;
- 查询有绩效的人数,和有管理费的人数:
SELECT COUNT(performance), COUNT(manage) FROM employee;
2. SUM和AVG
SELECT SUM(salary) FROM employee;
- 查询所有雇员月薪和,以及所有雇员绩效和
SELECT SUM(salary), SUM(performance) FROM employee;
- 查询所有雇员月薪+绩效和:
SELECT SUM(salary+IFNULL(performance,0)) FROM employee;
- 统计所有员工平均工资:
SELECT AVG(salary) FROM employee;
3. MAX和MIN
查询最高工资和最低工资:
SELECT MAX(salary), MIN(salary) FROM employee;
9. 分组查询
什么是分组查询
将查询结果按照1个或多个字段进行分组,字段值相同的为一组
分组使用
SELECT gender from employee GROUP BY gender;
根据gender字段来分组,gender字段的全部值只有两个('男'和'女'),所以分为了两组 当group by单独使用时,只显示出每组的第一条记录 所以group by单独使用时的实际意义不大
group_concat(字段名)可以作为一个输出字段来使用 表示分组之后,根据分组结果,使用group_concat()来放置每一组的某字段的值的集合
SELECT gender,GROUP_CONCAT(name) from employee GROUP BY gender;
- group by + 聚合函数
通过group_concat()的启发,我们既然可以统计出每个分组的某字段的值的集合,那么我们也可以通过集合函数来对这个"值的集合"做一些操作
查询每个部门的部门名称和每个部门的工资和
SELECT department,SUM(salary) FROM employee GROUP BY department;
查询每个部门的部门名称以及每个部门的人数
SELECT department,COUNT(*) FROM employee GROUP BY department;
查询每个部门的部门名称以及每个部门工资大于1500的人数
SELECT department,COUNT(salary) FROM employee WHERE salary > 1500 GROUP BY department;
- group by + having
用来分组查询后指定一些条件来输出查询结果 having作用和where一样,但having只能用于group by
查询工资总和大于9000的部门名称以及工资和
SELECT department,GROUP_CONCAT(salary) FROM employee GROUP BY department;
SELECT department,SUM(salary) FROM employee GROUP BY department;
总和大于9000
SELECT department,SUM(salary) FROM employee GROUP BY department HAVING SUM(salary)>9000;
- having与where的区别
having是在分组后对数据进行过滤. where是在分组前对数据进行过滤 having后面可以使用分组函数(统计函数) where后面不可以使用分组函数 WHERE是对分组前记录的条件,如果某行记录没有满足WHERE子句的条件,那么这行记录不会参加分组;而HAVING是对分组后数据的约束。
查询工资大于2000的,工资总和大于6000的部门名称以及工资和
SELECT * FROM employee WHERE salary >2000;
- 各部门工资
SELECT department, GROUP_CONCAT(salary) FROM employee WHERE salary >2000 GROUP BY department;
- 各部门工资总和
SELECT department, SUM(salary) FROM employee WHERE salary >2000 GROUP BY department;
- 各部门工资总和大于6000
SELECT department, SUM(salary) FROM employee WHERE salary >2000 GROUP BY department HAVING SUM(salary)>6000;
- 各部门工资总和大于6000降序排列
SELECT department, SUM(salary) FROM employee
WHERE salary >2000
GROUP BY department
HAVING SUM(salary)>6000
ORDER BY SUM(salary) DESC;
10. LIMIT
从哪一行开始查,总共要查几行 Limit 参数1,参数2
角标是从0开始
格式:
select * from 表名 limit 0,3;