搭建 Telegraf + InfluxDB + Grafana 监控遇到几个小问题,
1:如果同一台服务器上安装有多个MongoDB实例,telegraf.conf 中关于 MongoDB 如何配置?配置数据在【INPUT PLUGINS的[[inputs.mongodb]]】部分。
单个实例配置
servers = ["mongodb://UID:PWD@XXX.XXX.XXX.124:27218"]
错误的多实例配置(例如两个实例);
servers = ["mongodb://UID:PWD@XXX.XXX.XXX.124:27218"] servers = ["mongodb://UID:PWD@XXX0.XXX.XXX.124:27213"]
重启服务,查看服务状态,提示错误信息如下;
Failed to start The plugin-driven server agent for reporting metrics into InfluxDB.

正确的配置应该为;
servers = ["mongodb://UID:PWD@XXX.XXX.XXX.124:27213","mongodb://UID:PWD@XXX.XXX.XXX.124:27218"]
2.配置Grafana 告警规则后,发现只是告警一次,后面恢复后再报警一次。即异常持续期间没有一直告警。
解决办法,这个设置其实在【Alterting】--》【Notification channels】-->【Send reminders】
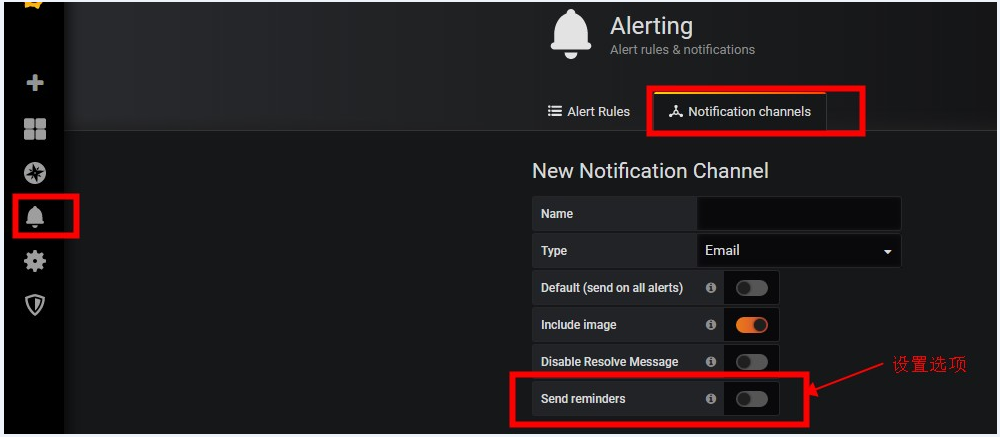
例如以下的设置可以理解为,每5分钟触发一下告警信息。

3.告警检查显示没有数据。
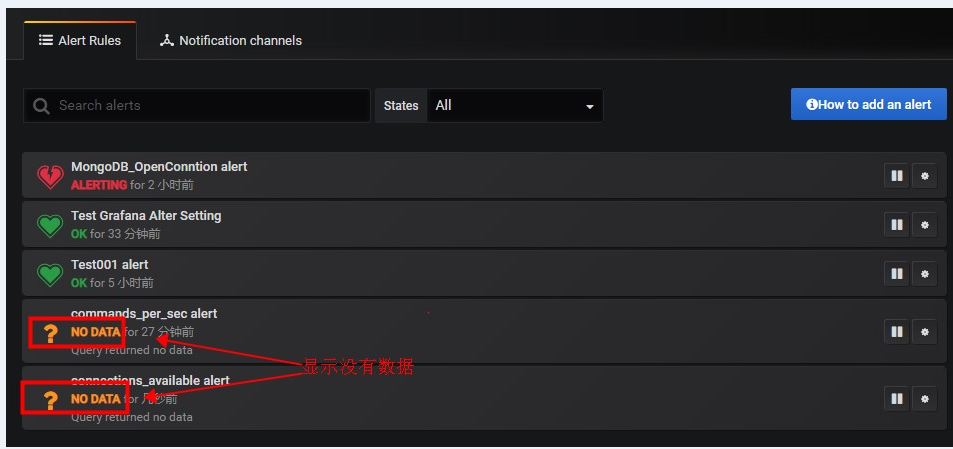
这个时候有两种原因
(1)收集监控项的代理程序有问题 ;
(2)或者是代理程序没问题,是汇报数据不及时的问题。
针对第二问题,我们可以调整代理程序执行频率;如果实时性要求不是很高,还可以调整告警规则检查数据的时间范围。
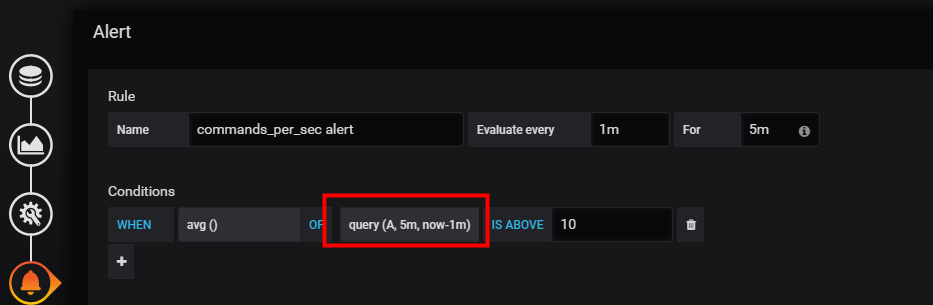
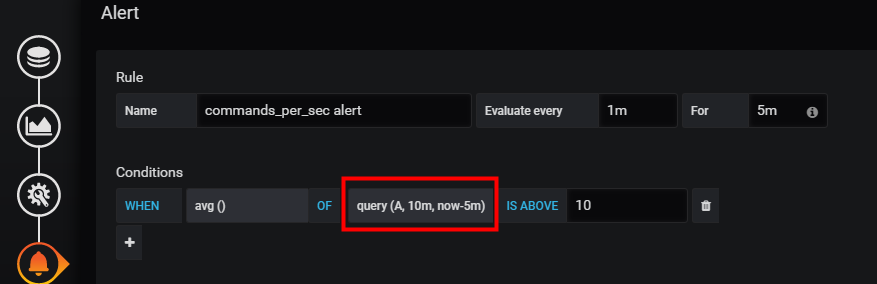
例如,我们可以从检查 过去5分钟到过去1分钟内的数据,调整为过去10分钟到过去5分钟内的数据。对应的设置如下:
调整前;
调整后
4.随着需要监控的子项的增多,收集时间必然增多,需要调整运行周期。
否则,报错信息如下;
telegraf[2908]: 2019-03-01T02:40:46Z E! Error in plugin [inputs.mysql]: took longer to collect than collection interval (10s)
解决方案:调整 telegraf.conf 文件中 [agent] 部分的interval参数。

本站文章为和通数据库网友分享或者投稿,欢迎任何形式的转载,但请务必注明出处.
同时文章内容如有侵犯了您的权益,请联系QQ:970679559,我们会在尽快处理。