利用NoSQL API最大程度提升数据访问速度
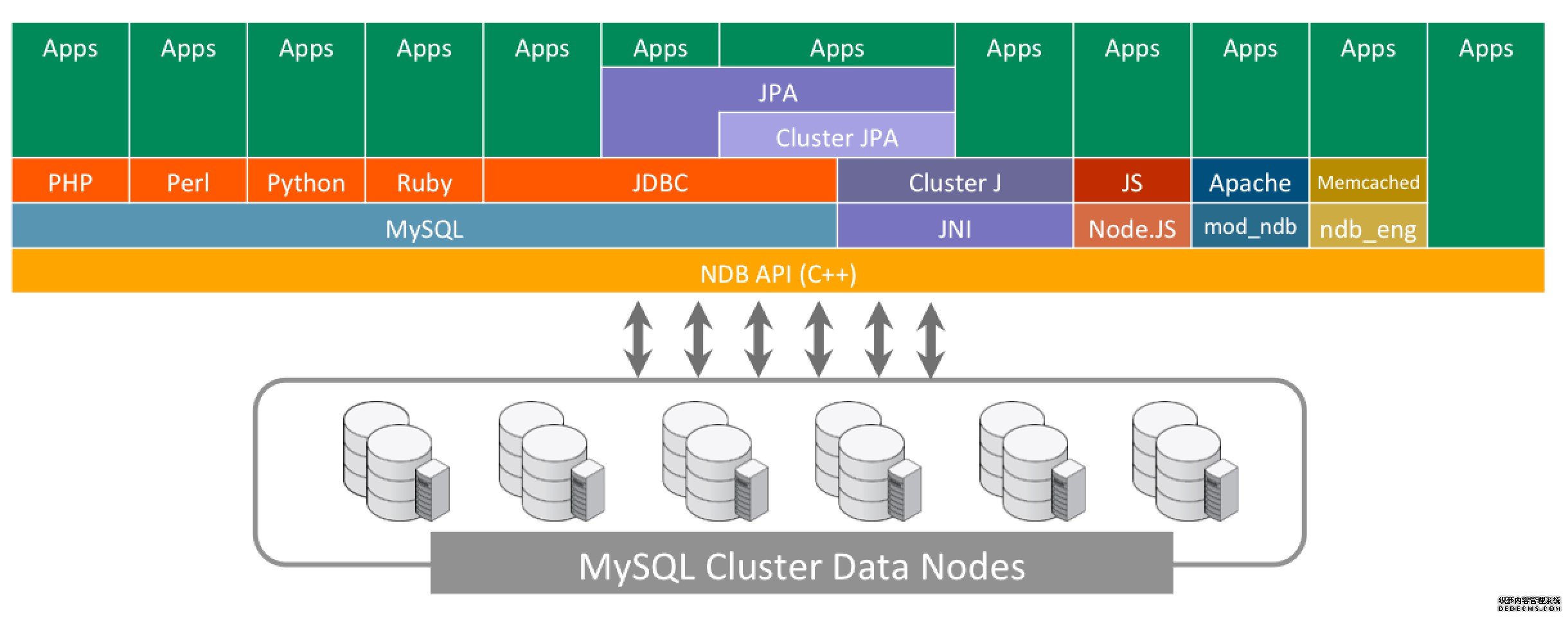
MySQL Cluster提供多种方式对存储数据进行访问; 最常见的方法当然是SQL,不过正如下图所示,我们还可以利用多种原生API帮助应用程序直接从数据库当中读取及写入数据,同时又能通过转换为SQL以绕过MySQL Server的方式防止效率低下或者拉高开发复杂程度。现有API面向C++、Java、JPA、JavaScript/Node.js、HTTP以及Memcached协议。
基准目标:每秒2亿次查询
MySQL Cluster在设计当中主要面向两种工作负载类型:
-OLTP(即联机事务处理):内存优化型表提供次毫秒级低延迟与堪称极端水平的OLTP工作负载并发能力,同时仍然保证良好的耐久性表现; 此外,其也能够被用于处理基于磁盘的表数据。
-临时性搜索:MySQL Cluster增加了并行数量上限,从而在对表内非索引数据列进行扫描时带来显著的速度提升。
值得一提的是,MySQL Cluster在处理OLTP工作负载方面的表现最为突出,特别是在以并发方式发出海量查询/事务请求的情况下。为此,我们一般会使用flexAsynch基准测试来衡量将更多数据节点添加到集群当中后,NoSQL所获得的实际性能扩展效果。
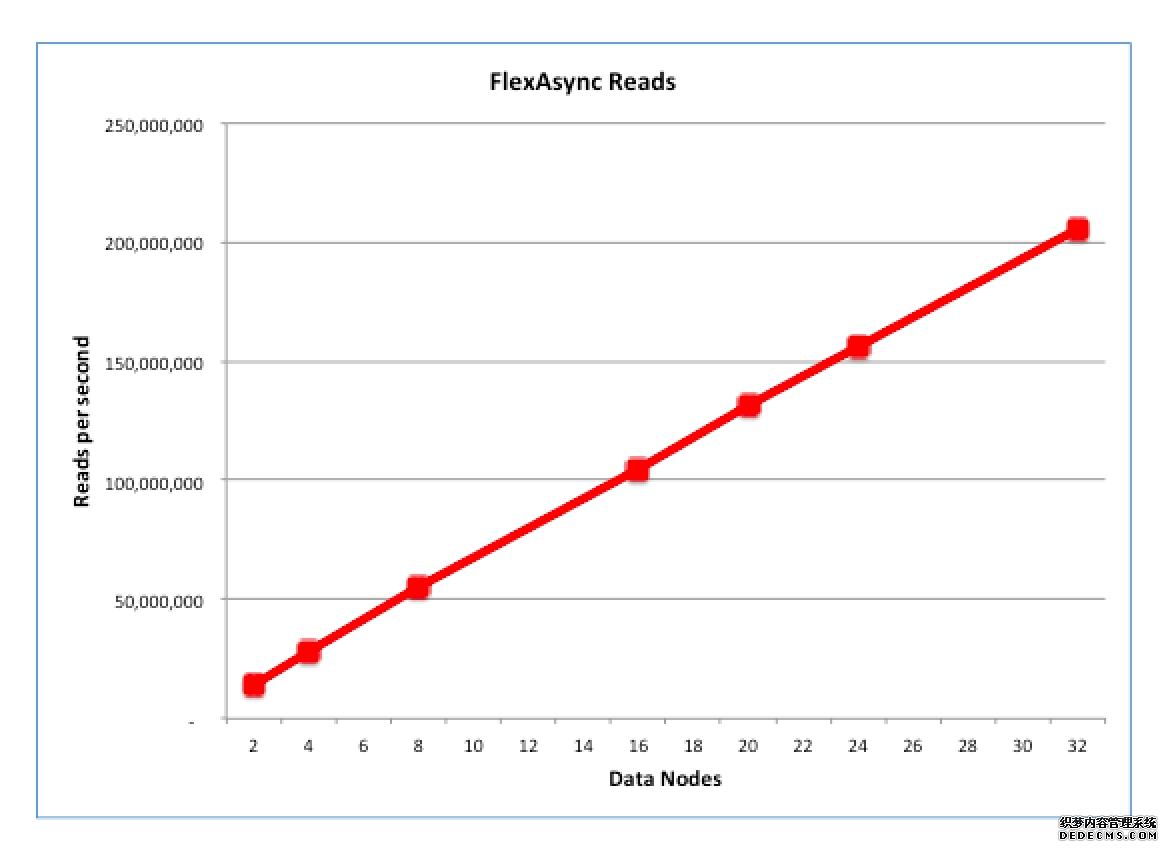
此次基准测试所面向的每个数据节点都运行在采用专用56线程英特尔E5-2697 v3(Haswell架构)设备之上。上图所示为数据吞吐能力随数据节点数量增长的变化趋势,具体区间由2节点最终增加到32节点(请注意,MySQL Cluster目前最多能够支持48个数据节点)。如套大家所见,整个扩展比例几乎保持线性,而且在32数据中心情况下其整体吞吐能力达到了每秒2亿次NoSQL查询。
如果大家对这次测试感兴趣,可以点击此处在MySQL Cluster基准测试页面内了解与之相关的详尽描述与最新结果。
此次2亿QPS基准测试运行在MySQL Cluster 7.4版本之上(为目前最新的通用版本)——大家可以点击此处了解更多与MySQL Cluster 7.4版本相关的信息,或者点击此处观看主题网络研讨会的重播视频。
原文标题:How MySQL Is Able To Scale To 200 Million QPS - MySQL Cluster
