数据库分区实现
下边,我们以 IBM InfoSphere Balanced Warehouse E7100 为例,介绍一下DB2 分区数据库在AIX下的基本管理方法及应用实践。DB2 分区数据库在 Windows 环境下的管理方法和 AIX 略有不同,具体请参阅相关手册。
IBM InfoSphere Balanced Warehouse 是IBM针对客户数据仓库系统提出的一整套完整的解决方案。当用户实施一个数据仓库系统时,对用户来说,一个非常大的挑战就是未来的数据仓库系统应该选择什么样的服务器,服务器的配置是什么,选择多少台服务器;选择什么样的存储设备,存储容量要多大,存储设备配置是什么;选择什么样的网络设备,它的配置是什么才能保证系统性能高效、稳定。同时,随着系统的应用,数据量会急剧增长,如何在保证系统性能的前提下,提供更好的系统扩展能力也是用户非常关心的问题。为了解决上述问题,IBM 结合自己多年实施客户数据仓库系统的经验,并协同IBM软件部门、服务器部门、存储部门及实验室,共同推出了 InfoSphere Balanced Warehouse 解决方案,有时也称为 BCU(Balanced Configuration Unit)。InfoSphere Balanced Warehouse 是一个包含服务器、存储、数据仓库软件在内的完整解决方案,它基于 IBM 最佳实践并得到充分验证,是一个预先配置好的、可立即使用的解决方案,客户无需靠猜测或假象去配置并验证,实现开箱即用。InfoSphere Balanced Warehouse 采用平衡的理念,每个组件(数据库、服务器和存储)提供均衡的性能确保整体方案性能最优。同时,它采用可扩展的模块化设计,数据仓库系统在整个生命周期中,可以以增量的方式进行扩展,达到的性能可预见、可度量。
InfoSphere Balanced Warehouse主要由以下几个模块组成:如下图:
图 3. InfoSphere Balanced Warehouse 模块组成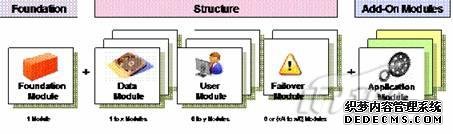
Foundation Module: 有时也称为 administration BCU。该模块主要包括编目分区、协调分区以及单分区表。系统必须要有 1 个 Foundation Module。
Data Module: 有时也称为 data BCU。该模块主要保存分区表数据。根据数据量,可以有 1 个或多个 Data Module。
User Module: 如果系统有大量用户访问,我们可以考虑增加 User Module。
Failover Module: 用于满足 HA 的需求。
Application Module: 用于运行应用程序,比如说 ETL 应用就可以配置在 Application Module 上。
本次配置环境包括一个 administration BCU 和 2 个 data BCU,如下图所示:
图 4. InfoSphere Balanced Warehouse 配置图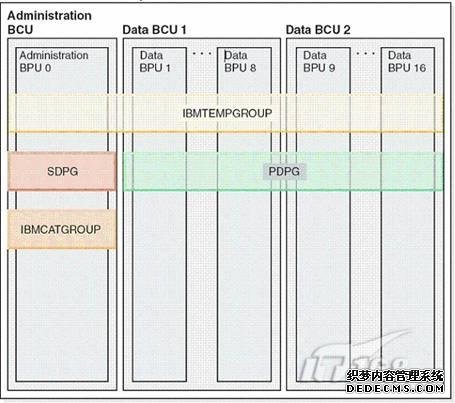
创建实例及配置通信连接
使用db2icrt命令创建实例
/opt/IBM/db2/V9.1/instance/db2icrt -u bcufenc bcuaix |
配置TCPIP通信服务
db2set DB2COMM=tcpip |
修改DBM CFG 中的 SVCENAME参数
db2 update dbm config using svcename xbcuaix |
在实例级禁用fault monitor
db2fm -i instance_name -f no |
创建诊断文件目录
缺省的情况下,db2diag.log 文件创建在 ~/sqllib/db2dump 目录下,这个目录是 NFS-mounted,我们一般建议要将 db2diag.log 文件放在非 NFS-mounted 目录下。在 E7100 实施中,我们建议将该文件放到外部的存储上。
Administration BCU:
mkdir -p /db2path/bcuaix/NODE0000/SQL00001/db2dump
Data BCU 1:
mkdir -p /db2path/bcuaix/NODE0001/SQL00001/db2dump
Data BCU 2:
mkdir -p /db2path/bcuaix/NODE0009/SQL00001/db2dump
Administration BCU:
ln -s /db2path/bcuaix/NODE0000/SQL00001/db2dump /db2path/bcuaix/db2dump
Data BCU 1:
ln -s /db2path/bcuaix/NODE0001/SQL00001/db2dump /db2path/bcuaix/db2dump
Data BCU 2:
ln -s /db2path/bcuaix/NODE0009/SQL00001/db2dump /db2path/bcuaix/db2dump
db2 update dbm config using diagpath /db2path/bcuaix/db2dump
定义数据库分区
在数据库分区环境下,数据库被分为多个分区,分区之间彼此独立工作,实现并行操作。数据库分区可以是物理分区也可以是逻辑分区。在一台物理机器上部署的一个分区,我们称为物理分区,如果是在一台 SMP 机器上部署多个分区,这些分区我们称为逻辑分区。我们可以选择物理分区,也可以选择逻辑分区。通常,如果决定采用大的 SMP 机器,有更多的 CPU、内存及硬盘,我们会采用逻辑分区;如果决定采用多台物理机器,我们会通过非共享的体系结构采用物理分区;如果决定采用多台 SMP 机器,我们则会采用物理分区和逻辑分区结合的方式。
在 DB2 数据库分区环境中,执行 CREATE DATABASE 语句所在的分区称为编目分区(catalog partition)。编目分区保存系统编目表。编目分区只能创建在一个分区上。通常,在实际生产环境中,我们建议采用一个专用编目分区,这个分区只包含编目表,不包含用户数据。这对 DB2 的一些实用程序运行效率有较大的提高。比如说 BACKUP 和 RESTORE 命令,需要先在编目分区上运行,之后才能在其他分区上执行。由于编目分区上没有用户数据,因此它的备份和恢复就可以很快完成,并且可以最小程度地延迟对其他分区的(并行)操作的开始。
在 DB2 数据库分区环境中,应用程序连接的分区,我们称为协调分区(coordinate partition)。它负责处理用户的请求,并根据 Partition key 将用户的请求分解成多个子任务交由不同分区并行处理,最后将不同分区的执行结果经过汇总返回给用户。任何一个数据库分区都可以是协调分区。在实际生产环境中,我们建议采用一个或几个专用协调分区。因为应用程序要通过一个或多个协调分区为用户连接转移大量的数据的话,那么就会消耗那些分区上的大部分 CPU,并降慢了数据访问速度。如果让分区什么也不做,只是充当协调者(coordinator),就不会降低数据分区数据访问速度。
在 InfoSphere Balanced Warehouse E7100 的设计中,我们在 administration BCU 中,分别为编目分区和协调分区分配了专用的分区,同时,根据数据库分区的基本原则,我们将系统中的小表创建在了一个单一分区上。用户的数据,我们创建在 data BCU 上,同时,根据数据库分区的基本原则,我们将系统中的大表尽量地分布到 data BCU 上的所有分区上。当用户数据增加后,我们可以通过增加更多的 data BCU 来实现增量的方式扩展、提供均衡的性能。如下说明:
Database partition 0 (BPU 0) 包含:
Catalog function (only one database partition has the database catalog)
Coordinator function
Single-partition data function
Query Patroller server and control tables (if implemented)
Located on the administration BCU
Database partition 1 - n (BPU1 - BPUn) 包含:
Database partitions with partitioned data
Located on the data BCUs
DB2 节点配置文件(db2nodes.cfg)
用来定义数据库分区。在创建分区数据库之前,一定要先定义 db2nodes.cfg 文件。该文件放置在用户实例主目录下。系统中的每一个分区在该文件中都会有一项。
db2nodes.cfg 文件的基本格式如下:
dbpartitionnum hostname logical-port netnam |
其中:
dbpartitionnum
数据库分区号唯一地定义数据库分区,可在 0 到 999 之间。数据库分区号必须以升序顺序排序。该顺序中可以有间隔。一旦指定了数据库分区号,就不能对其进行更改。否则,分布图(它指定数据分发方式)中的信息可能不正确。
hostname
用作分区间通信的 IP 地址的主机名。
logical-port
它指定该数据库分区的逻辑端口号。此号码与数据库管理器实例名一起用来标识 etc/services 文件中的 TCP/IP 服务名称条目。 对于每个主机名,一个逻辑端口必须为 0(零) 。
netname
指定用于 FCM 高速互联的主机名称 。
下边是包括一个 administration BCU 和 2 个 data BCU 环境的 db2nodes.cfg 文件内容:
0 adminbcu001 0 adminbcu001_fcm
1 databcu001 0 databcu001_fcm
2 databcu001 1 databcu001_fcm
3 databcu001 2 databcu001_fcm
4 databcu001 3 databcu001_fcm
5 databcu001 4 databcu001_fcm
6 databcu001 5 databcu001_fcm
7 databcu001 6 databcu001_fcm
8 databcu001 7 databcu001_fcm
9 databcu002 0 databcu002_fcm
10 databcu002 1 databcu002_fcm
11 databcu002 2 databcu002_fcm
12 databcu002 3 databcu002_fcm
13 databcu002 4 databcu002_fcm
14 databcu002 5 databcu002_fcm
15 databcu002 6 databcu002_fcm
16 databcu002 7 databcu002_fcm
在分区号的分配上,我们建议,catalog partition 分区号分配为 0,因为一个实例下只能有 1 个 catalog partition,分区号 990-999 分配给另外需要增加的 coordinator partitions,分区号 980-989 分配给另外需要增加的单分区的表。
配置分区间通信
在 DB2 数据库分区环境中,分区之间需要通过 DB2 Fast Communication
Manager 进行通信。在 /etc/services 文件中,需要为 DB2 FCM 通信设置相应的通信端口。
xbcuaix 50000/tcp xbcuaix_int 50001/tcp DB2_bcuaix 60000/tcp DB2_bcuaix_END 60016/tcp |
创建数据库
我们在 administration BCU 上创建数据库testdb。
db2 "create database testdb automatic storage no on /db2path \ pagesize 16384 autoconfigure apply none" |
创建数据库分区组(database partition groups)
数据库分区组是一个或多个数据库分区的集合。在 DB2 数据库分区环境中,数据库表空间创建在数据库分区组中。
在设计数据库分区组时,我们一般建议:
几乎总要为小的表创建至少一个单分区的数据库分区组。
几乎总要为大的表使用至少一个由所有分区组成的数据库分区组。这个数据库分区组可以是缺省的 IBMDEFAULTGROUP。
分区数越多,就越可能存在一些对单分区来说太大、而要展开到所有分区上又太小的表,那么就越需要创建包含数个分区、但不是全部分区的数据库分区组。
当我们创建一个数据库后,系统会缺省创建 3 个数据库分区组:
IBMCATGROUP:编目数据库分区组,用来存储系统编目表。它只包含一个数据库分区。
SYSCATSPACE 表空间创建在这个分区组中。
在 BCU 设计中,IBMCATGROUP 创建在 0 号数据库分区上。
IBMTEMPGROUP.:临时数据库分区组,tempspace1 系统临时表空间创建在这个分区组中。它包含系统中的所有数据库分区。
IBMDEFAULTGROUP:缺省数据库分区组。用户表空间缺省创建在该分区组中。USERSPACE1 表空间包含在 IBMDEFAULTGROUP 中。
在BCU设计中,建议不使用IBMDEFAULTGROUP,而是创建了2个新的数据库分区组:
PDPG: 分布在data BCU分区上的数据包含在此数据库分区组中。PDPG 只包括data BCU 上的分区,但不包含administration BCU上的分区。它适用于中等数据规模到大数据规模的表。
SDPG:该数据库分区只包含 administration BCU 分区上的数据,它只包含一个数据库分区,即 0 号数据库分区。系统中的一些小表保存在此数据库分区组中,这些小表通常是一些维表(dimension tables)或 lookup tables。
CREATE DATABASE PARTITION GROUP PDPG ON DBPARTITIONNUMS (1 to 16) CREATE DATABASE PARTITION GROUP SDPG ON DBPARTITIONNUMS (0) |
创建 buffer pools
在本示例中,我们创建 2 个 16K 页的 buffer pools:
CREATE BUFFERPOOL BP_16K ALL DBPARTITIONNUMS SIZE 53760 PAGESIZE 16K; CREATE BUFFERPOOL BPTMP_16K ALL DBPARTITIONNUMS SIZE 10752 PAGESIZE 16K; |
创建表空间
在本次实例中,我们将创建如下表空间:
db2tmp ---临时表空间
ts_pd_data_001---分区表数据空间
ts_pd_idx_001---索引表空间
ts_sd_small---单分区表空间。如图所示:
图 5. 表空间创建示例图:
在 data BCU 上创建如下表空间:
CREATE TEMPORARY TABLESPACE db2tmp
IN DATABASE PARTITION GROUP ibmtempgroup
PAGESIZE 16K
MANAGED BY DATABASE
USING (
FILE ’/db2fs1p $N /bcuaix/databasename/db2tmp’ 25G)
ON DBPARTITIONNUMS (0)
USING (
FILE ’/db2fs1p $N /bcuaix/databasename/db2tmp’ 25G,
FILE ’/db2fs2p $N /bcuaix/databasename/db2tmp’ 25G,
FILE ’/db2fs3p $N /bcuaix/databasename/db2tmp’ 25G,
FILE ’/db2fs4p $N /bcuaix/databasename/db2tmp’ 25G)
ON DBPARTITIONNUMS (1 to 16)
EXTENTSIZE 16
PREFETCHSIZE AUTOMATIC
BUFFERPOOL BPTMP_16K
OVERHEAD 5.75 TRANSFERRATE 0.4
AUTORESIZE YES MAXSIZE 400G
NO FILE SYSTEM CACHING;
CREATE TABLESPACE ts_pd_data_001
IN DATABASE PARTITION GROUP pdpg
PAGESIZE 16K
MANAGED BY DATABASE
USING (
FILE ’/db2fs1p $N /bcuaix/databasename/ts_pd_data_001’ 50G,
FILE ’/db2fs2p $N /bcuaix/databasename/ts_pd_data_001’ 50G,
FILE ’/db2fs3p $N /bcuaix/databasename/ts_pd_data_001’ 50G,
FILE ’/db2fs4p $N /bcuaix/databasename/ts_pd_data_001’ 50G)
EXTENTSIZE 16
PREFETCHSIZE AUTOMATIC
BUFFERPOOL BP_16K
OVERHEAD 5.75 TRANSFERRATE 0.4
AUTORESIZE YES MAXSIZE 400G
NO FILE SYSTEM CACHING;
CREATE TABLESPACE ts_pd_idx_001
IN DATABASE PARTITION GROUP pdpg
PAGESIZE 16K
MANAGED BY DATABASE
USING (
FILE ’/db2fs1p $N /bcuaix/databasename/ts_pd_idx_001’ 25G,
FILE ’/db2fs2p $N /bcuaix/databasename/ts_pd_idx_001’ 25G,
FILE ’/db2f3p $N /bcuaix/databasename/ts_pd_idx_001’ 25G,
FILE ’/db2fs4p $N /bcuaix/databasename/ts_pd_idx_001’ 25G)
EXTENTSIZE 16
PREFETCHSIZE AUTOMATIC
BUFFERPOOL BP_16K
OVERHEAD 5.75 TRANSFERRATE 0.4
AUTORESIZE YES MAXSIZE 200G
NO FILE SYSTEM CACHING;
在administration BCU上创建如下表空间:
CREATE TABLESPACE ts_sd_small_001 |
在创建分区数据库表空间时,我们经常会使用数据库分区表达式。它是由参数 ' $N (注意在 $N 之前有一个空格)来指定的,DB2 会将 $N 替换成数据库分区组中已定义的分区号。
创建表
当创建数据库分区组时,每一个数据库分区组都会对应一个分区图(partitioning map),它是一个包含 4096 个条目的数组,每个条目的值对应于数据库分区组中的某一个分区号。
分区键(partitioning key)是由一个表上的一个列或者多个列组成,用于确定某一行特定数据分布在哪个分区上。分区键是在 CREATE TABLE 语句来定义的。如果没有指定分区键,缺省的分区键是主键的第一列,如果没有这么一列,则选择有适合数据类型的第一列。
当向表中插入一条记录时,DB2 将该记录的分区键值散列(hash)到分区图中的一个条目上,并根据该条目找到要使用的分区号。
在定义分区表时,分区键的定义对今后性能的影响非常大,因此,在选择上一定要慎重。通常,在选择分区键时,要遵从如下原则:
选择经常用于连接的列作为分区键。
分区键应该不包括经常更新的列。
除非一个表不是很重要,或者不知道一个好的分区键选择是什么,否则不应该随缺省情况选择分区键。缺省的分区键是主键的第一列,如果没有这么一列,则选择有适合数据类型的第一列。
将一个表创建为分区表之后,就不能直接更改它的分区键。
通过 ALTER TABLE 可以添加或删除分区键,但是这只对未分区表有效。
那些处于表上定义的惟一性约束或主键约束中的列必须是分区键的一个超集(superset)
数据类型:LOB 和 LONG 型的列不能作为分区键的一部分
就效率而言,整数类型的列是最可取的,其次是字符型,然后是小数。
选择基数较大的分区键列,以避免表中的行在各分区上分布不均衡。
在 DB2 数据库分区环境下,数据在不同分区的分布会影响表的连接策略。分区数据库环境下表连接策略主要包括:
并置连接(Collocated joins)--采用该种连接方式,表的连接以本地方式在数据所在的数据库分区上进行,不会在分区之间传输数据,这是效率最高的表连接方式。在分区数据环境下,应尽量采用该种连接方式。
定向连接(Directed joins)--采用该种连接方式,一个表中的数据会按照连接对中的另一个表的分区键值重新分发到其他分区上来完成表连接操作。它会在分区之间移动数据,对性能会有一定影响。当并置连接及未被采用,DB2优化器会选择定向连接方式。
广播连接( Broadcast joins)--采用该种连接方式,一个表中的所有数据会广播到另外表所在的所有分区上来完成表连接操作。如果在分区之间广播的数据量较大,对性能影响也会很大。当并置连接及定向表连接未被采用,DB2 优化器会选择广播连接方式。
在 DB2 数据库分区环境下,应尽量采用并置连接方式。要使用并置连接方式,被并置的表必须:
在相同的数据库分区组内
分区键必须有相同数量的列。
分区键中相应的列必须是分区兼容的。
分区兼容性是在分区键中相应列的基本数据类型之间定义的。分区兼容的(partition-compatible)数据类型有一个特性,那就是对于两种不同类型的两个变量,假设变量有相同的值,则它们将通过相同的分区函数映射到相同的分区键索引。分区兼容性有以下特征:
内部格式用于 DATE、TIME 和 TIMESTAMP。这些类型彼此不兼容,并且没有哪一个与 CHAR 或 VARCHAR 兼容。
分区兼容性不受具有 NOT NULL 或 FOR BIT DATA 定义的列的影响。
对于兼容数据类型的 NULL 值是一致处理的。而不兼容数据类型的 NULL 值可能产生不同的结果。
可以使用 UDT 的基本数据类型来分析分区兼容性。
分区键中具有相同值的小数是一致处理的,即使它们的标度(scale)和精度(precision)不一样也是如此。
系统提供的散列函数将忽略字符串(CHAR、VARCHAR、GRAPHIC 或 VARGRAPHIC)的结尾空白。
不同长度的 CHAR 或 VARCHAR 是兼容的数据类型。
相等的 REAL 或 DOUBLE 值,即使它们的精度不同,也将被一致处理。
另外,我们也经常使用复制的具体化查询表(replicated MQT)来实现并置连接。我们往往会选择更新不多而又经常与大表进行连接的小表或中等大小的表来作为复制的具体化查询表。
下面是对复制表的一个示例定义:
create table t1_rep as (select * from t1) data initially deferred \ refresh deferred in ts_pd_data_001 replicated |
下边的例子,我们在 ts_pd_data_001 表空间上创建一个 LINEITEM 表:
CREATE TABLE "DB2INST1"."LINEITEM" (
"L_ORDERKEY" INTEGER NOT NULL ,
"L_PARTKEY" INTEGER NOT NULL ,
"L_SUPPKEY" INTEGER NOT NULL ,
"L_LINENUMBER" INTEGER NOT NULL ,
"L_QUANTITY" DECIMAL(15,2) NOT NULL ,
"L_EXTENDEDPRICE" DECIMAL(15,2) NOT NULL ,
"L_DISCOUNT" DECIMAL(15,2) NOT NULL ,
"L_TAX" DECIMAL(15,2) NOT NULL ,
"L_RETURNFLAG" CHAR(1) NOT NULL ,
"L_LINESTATUS" CHAR(1) NOT NULL ,
"L_SHIPDATE" DATE NOT NULL ,
"L_COMMITDATE" DATE NOT NULL ,
"L_RECEIPTDATE" DATE NOT NULL ,
"L_SHIPINSTRUCT" CHAR(25) NOT NULL ,
"L_SHIPMODE" CHAR(10) NOT NULL ,
"L_COMMENT" VARCHAR(44) NOT NULL )
DISTRIBUTE BY HASH("L_ORDERKEY")
IN " ts_pd_data_001"